Repository는 인프라적인 요소에 가깝다고 할 수 있다. 그런데, 이 repository를 도메인 모델에서 직접 사용해도 괜찮을까? DDD와 관련된 여러 참고 문서들에서는 이에 대해 통일되지 않은 견해를 보이고 있다. 이 글을 통해 여러 견해들을 한꺼번에 모아서 생각해보자.
Domain model에서 repository를 직접 사용해도 될까? - 도메인 모델의 영속성 무지
Domain model과 repository의 의존성
결론부터 말하면, domain model에서 repository를 직접 사용하는 것은 지양해야 한다. Domain model은 순수하게 비즈니스 로직을 담는 곳이며, 인프라와 관련된 요소에 의해 영향을 받으면 안된다는 것이 DDD의 기본 중의 기본이다. 그런데, domain layer 전체에서 repository같은 인프라적인 요소를 전혀 사용할 수 없는가라는 질문에는 답변들이 다소 다르다. 상황에 따라 domain layer의 일부에서는 repository를 사용하는 것을 허용해야 한다는 주장도 있다. 다양한 주장들을 살펴보고, 최적의 설계 방법에 대해 알아보자.
아키텍처 관점에서의 domain layer 의존성 논란
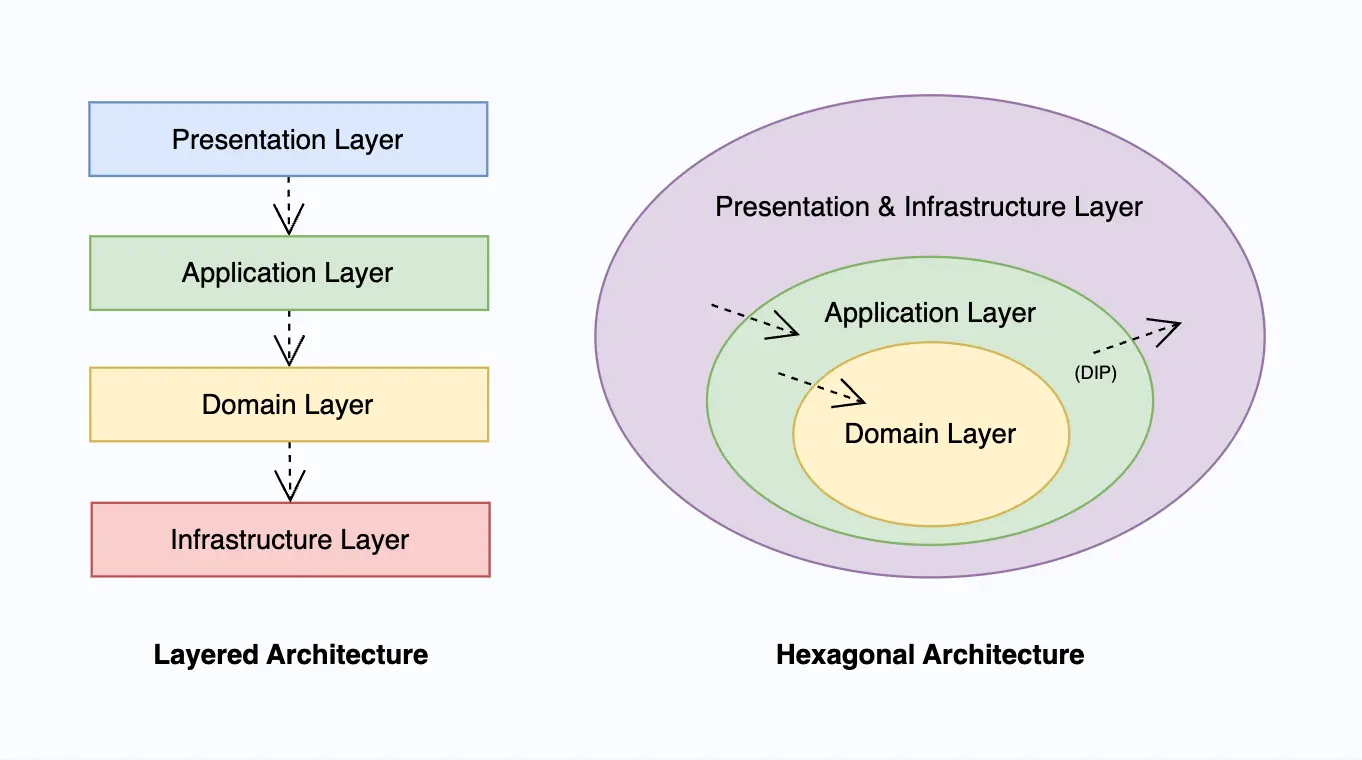
수많은 아키텍처 패턴들 중에서 가장 사랑받는 아키텍처 두 가지는 layered architecture와 hexagonal architecture라고 할 수 있다. 이때 Hexagonal architecture는 종종 양파 아키텍처, 클린 아키텍처, 또는 포트와 어댑터(ports and adapters)라고 불리기도 한다. 다양한 이름을 가지고 있는 만큼 미세하게 다른 부분들이 있겠지만 본질적으로는 거의 같은 패턴을 의미한다. Domain layer가 아키텍처의 중심에 있도록 구성하는 패턴이라고 생각하면 된다.
이 두 아키텍처 패턴 모두 DDD에서 당연하다시피 채택되고 있다. 두 아키텍처 패턴은 기본적으로 소프트웨어를 여러 계층으로 나눈다는 개념에서 출발한다. 상위 레이어에서는 하위 레이어를 참조할 수 있지만, 반대 방향으로는 참조할 수 없다는 간단한 규칙이 적용된다. 이 규칙이 거슬린다면 Dependency Inversion Principle(DIP)을 적용해야 한다. 두 아키텍처 패턴이 유사하다고 생각할 수 있지만, domain layer 주변을 자세히 보면 큰 차이가 있음을 확인할 수 있다.
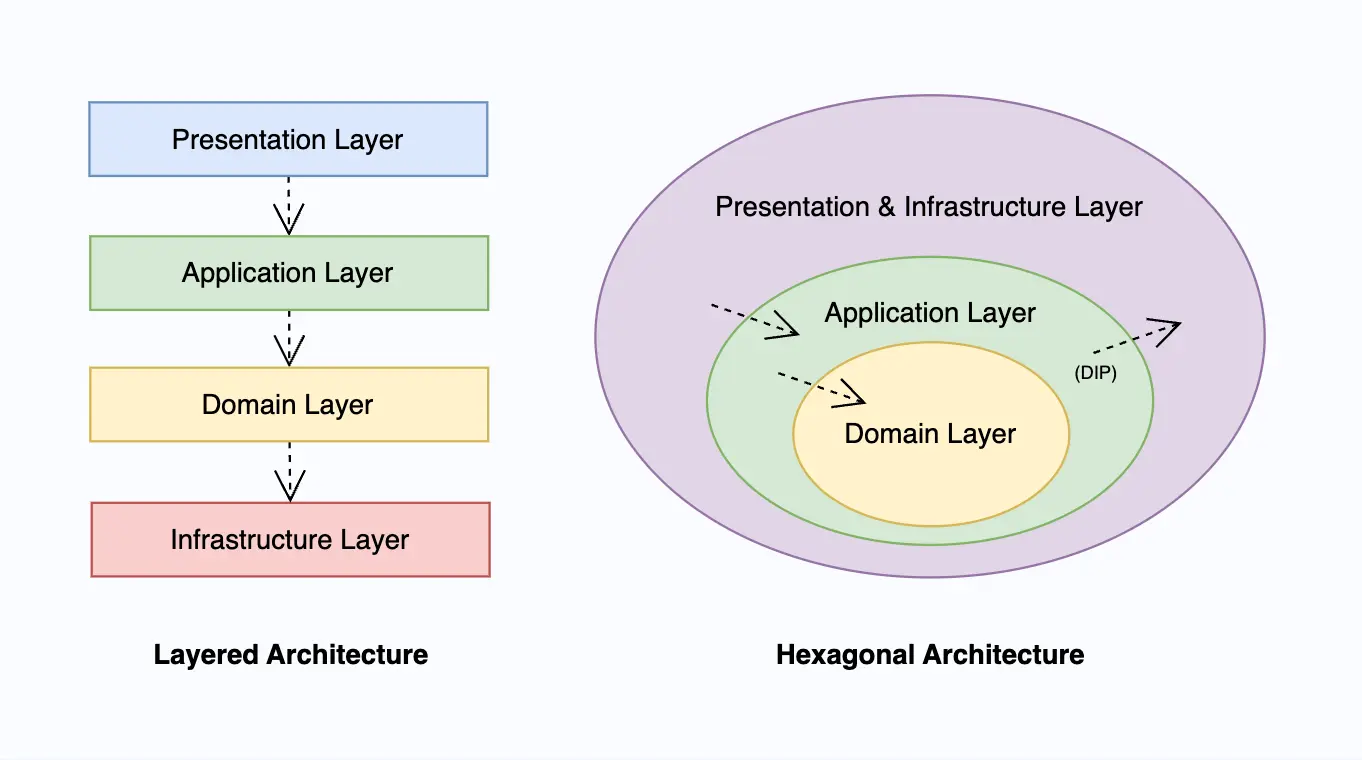
Layered architecture에서는 마치 domain layer가 infrastructure layer의 상위 레이어인 것처럼 표현된다. 이 말은 곧 domain model이 repository같은 인프라적인 요소를 직접 사용해도 된다는 것처럼 해석된다. 반면, hexagonal architecture에서는 domain layer가 아키텍처의 중심에 위치하여 그 어떤 다른 layer에도 의존성을 갖지 않는 것처럼 표현하고 있다. 이는 domain model이 repository를 직접 사용하는 것이 자엽스럽지 않다는 것을 시사한다.
Domain model 순수성을 둘러싼 의견 차이
Domain service에서는 repository를 사용해도 된다?
DDD에 대해 설명하는 서적들에서도 저자들 사이의 의견 차이가 보인다. 우선 Vaughn Vernon의 <Implementing Domain-Driven Design>에서는 domain model의 entity와 value object들의 집합인 aggregate에서 repository에 대한 의존성을 갖지 않는 것이 좋다고 주장한다. Domain model에서 repository에 대한 참조를 가지는 것을 단절된 도메인 모델(Disconnected Domain Model) 기법이라고 소개하면서, 이를 지양해야 한다고 언급한다.
일반적으로 리파지토리나 도메인 서비스의 애그리게잇으로의 의존성 주입은 나쁘다고 볼 수 있다. 이런 상황에서의 의존성 주입은 애그리게잇 내부에서 의존적 객체 인스턴스를 찾고 싶기 때문일 것이고, 그 객체가 다른 애그리게잇과 의존성을 갖고 있을 수 있다. '규칙: ID로 다른 애그리게잇을 참조하라' 절에서 언급했듯, 의존적 객체는 애그리게잇 커맨드 메소드가 호출되기 전에 찾아서 전달하는 편이 좋다. 단절된 도메인 모델(Disconnected Domain Model)은 일반적으로 덜 선호되는 접근법이다.
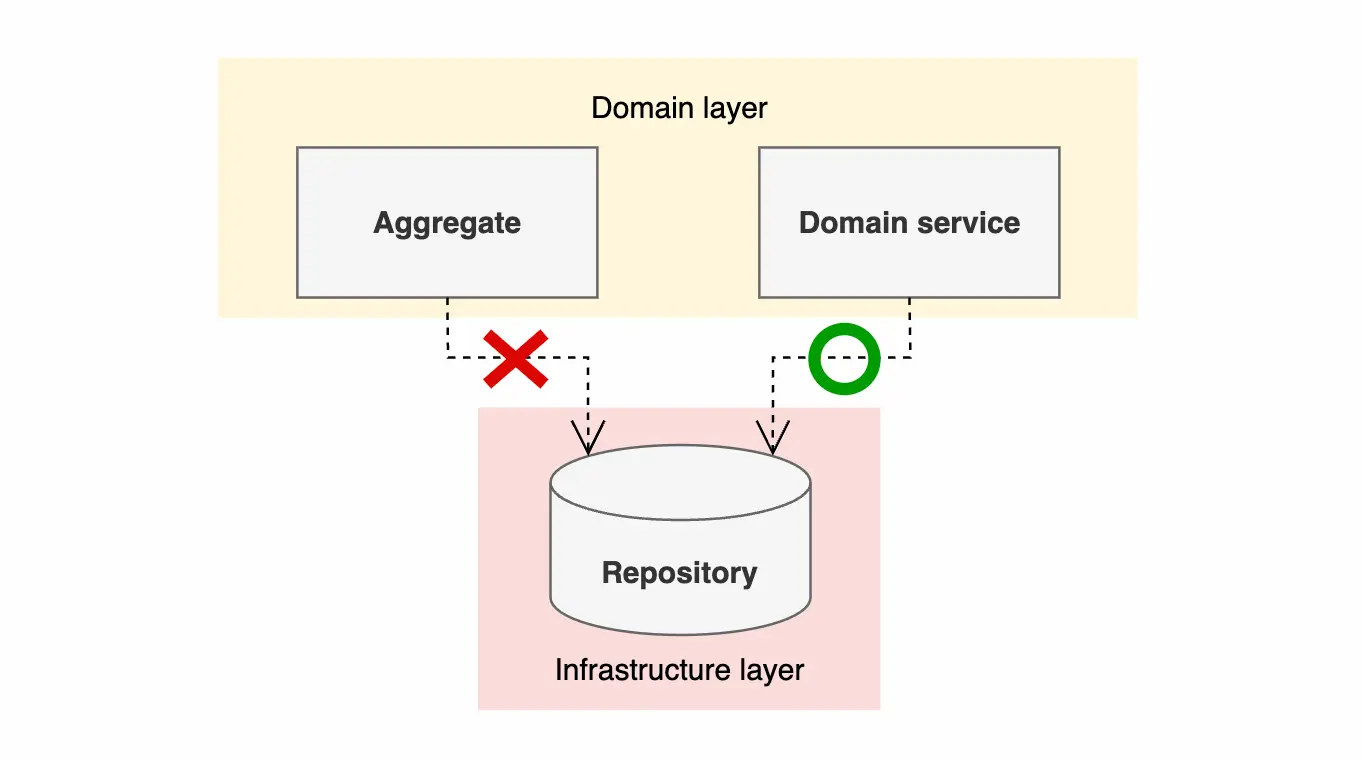
그런데, 혼란스럽게도 책의 곳곳에서는 domain service에서 repository를 직접 사용하는 예제들이 많이 등장한다. Vaughn Vernon은 aggregate에서는 이러한 의존관계를 지양해야 한다고 언급했지만, domain service에서 repository에 의존성을 갖는 것은 허용한다고 설명한다. 즉, domain layer의 일부에서는 repository를 사용하는 것을 어느정도 허용한다고 볼 수 있다.
도메인의 서비스는 필요에 따라 리파지토리를 사용할 수 있지만, 애그리게잇 인스턴스에서 리파지토리로의 접근은 추천하지 않는 방식이다.
Domain service에서도 repository를 사용하지 말자?
반면, Harry Percival의 저서 <Architecture Patterns with Python>에서는 domain model의 순수성과 영속성 무지에 대한 강조가 주를 이룬다. 쉽게 말해서, 앞서 그림으로 살펴본 hexagonal architecture의 의존관계를 엄격하게 지키는 것을 추천하고 있다고 볼 수 있다. 심지어 ORM을 사용할 때에도 DB와 관련된 정보가 domain model에 아예 노출되지 않도록 imperative mapping style을 써서 엄격히 분리해야 한다고 주장하고 있다. 이에 대한 자세한 내용은 이 글에서 이미 다루었다.
도메인 모델에는 그 어떤 의존성도 없기 바란다. 하부 구조와 관련된 문제가 도메인 모델에 지속적으로 영향을 끼쳐서 단위 테스트를 느리게 하고 도메인 모델을 변경할 능력이 감소되는 것을 원하지 않는다.
도메인 모델은 인프라에 대해 걱정할 필요가 없어야 한다. ORM은 모델을 임포트해야 하며 모델이 ORM을 임포트해서는 안된다.
Harry Percival의 견해는 application service와 domain service의 차이를 설명하는 부분에서 더욱 명확히 드러난다. Repository와 소통하는 것은 domain service가 아니라 application service의 전적인 책임이라는 관점이다. DB에서 domain entity를 꺼내오고 해당 객체를 통해 비즈니스 로직 수행을 위임한 뒤 변경사항을 다시 DB에 업데이트해주는 과정은 소프트웨어 곳곳에서 거의 공통적으로 수행되는 반복 작업일 뿐이다. 이러한 작업들은 비즈니스 로직과는 명확히 구분되는 행위라고 볼 수 있다.
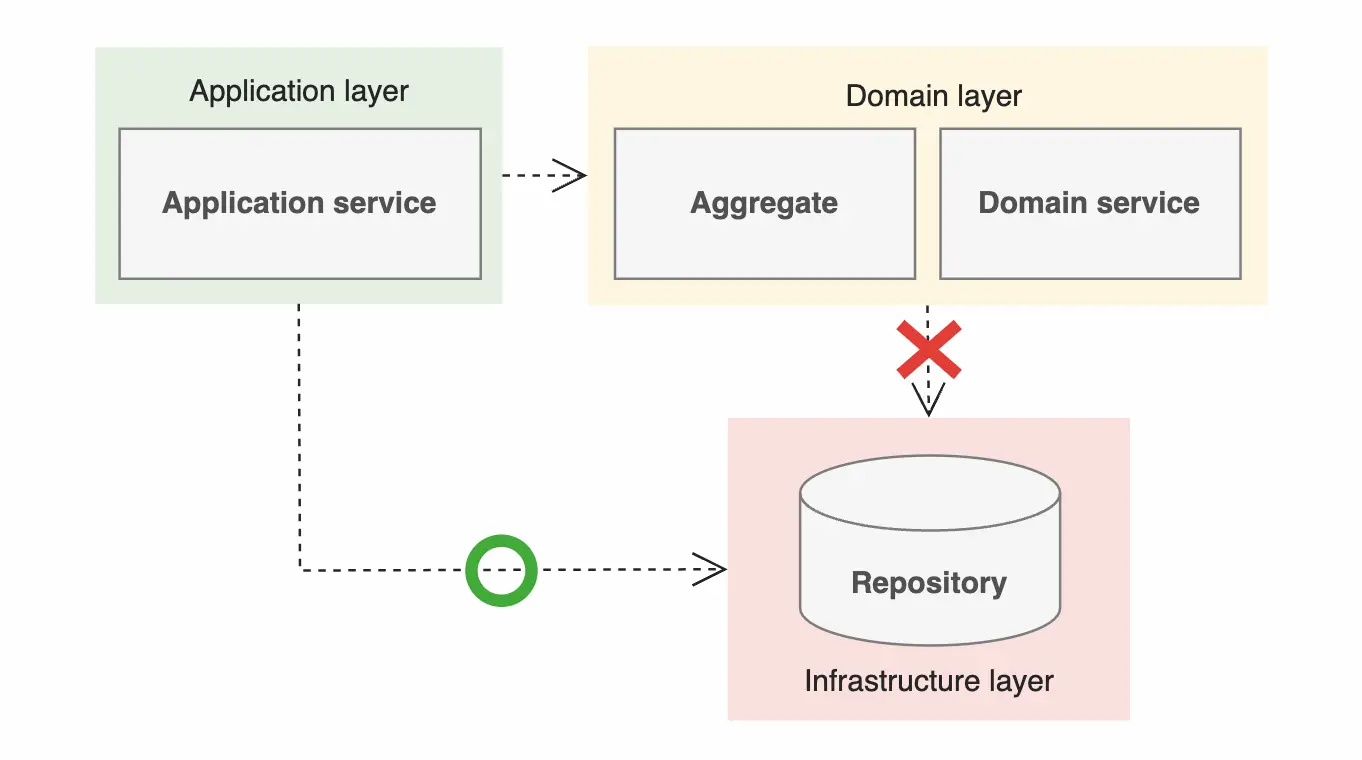
따라서, 책의 예제들을 보면 Vaughn Vernon의 예시들과는 달리 repository의 참조는 application service만 가지고 있고, domain service의 비즈니스 로직 수행에 필요한 객체들은 application service가 repository에서 대신 꺼내어 전달해주는 식으로 구성되어 있다.
분석: 충돌하는 의견들 하나로 종합 정리하기
전통적인 계층 아키텍쳐는 잊어버리자
우선 architecture 관점에서는 사실 어느정도 결론이 정해져 있긴 하다. DDD의 관점에서는 layered architecture가 다소 전통적이고 구시대적인 것이라고 치부한다. Hexagonal architecture가 상대적으로 더 현대적인 것이며, 이것이 전통적인 layered architecture의 대안이 될 수 있다는 식으로 설명한다. 앞서 언급한 두 저자들도 마찬가지다. 상대적으로 전통적인 쪽에 가까운 Vaughn Vernon의 말을 인용해보겠다.
그런데 전통적인 계층을 사용하면 도메인과 관련된 몇 가지 문제가 발생한다. 계층을 사용하면 도메인 계층에서 인프라 계층을 사용할 때 제약을 둬야 할 수 있다. 그렇다고 핵심 도메인 객체가 이를 사용할 수 있다는 의미는 아니며, 이런 상황은 무조건 피하도록 해야 한다.
Domain service의 repository 사용 정당화
Vaughn Vernon과 Harry Percival 둘 다 domain layer에서 repository를 사용하는 것을 지양해야 한다고 주장하고 있다. 무엇보다 aggregate에서 repository를 직접 사용하지 말아야 한다는 것에는 둘의 의견 차이가 없다. 단 한 가지 차이점은 domain service에서 repository의 참조를 사용해서 필요한 entity들을 직접 꺼내는 것을 허용하는지의 여부이다. 위 인용문만 봐도 Vaughn Vernon은 domain layer에서 인프라 계층에 의존하는 것을 피해야 한다고 주장하고 있는데, 모순적으로 domain service에서는 repository를 참조해도 된다는 입장이다.
변호하자면 Vaughn Vernon이 하고자 하는 말은 어디까지나 "경우에 따라", "때때로", 즉, 제한적으로 domain service의 repository 사용을 허용한다는 것으로 이해할 수 있다. 이러한 뉘앙스를 이해하려면 이전 글에서 다룬 aggregate 리팩토링 방법에 대해 이해할 필요가 있다. 짧게 요약하자면, 트랜잭션적 경계인 aggregate 안에 entity가 하나만 남을 때까지 잘게 쪼개고, 만약 다른 entity에 대한 정보가 필요한 경우에는 composition을 통해 직접 객체 참조를 하지 말고, ID 값만 가지고 있도록 리팩토링하라는 것이다.
@dataclass
class BadAggregate:
member: MemberAggregate
def get_member_name(self) -> str:
return self.member.get_name()
@dataclass
class GoodAggregate:
member_id: int
def get_member_name(self) -> str:
return ? # How can I get this without repository?
어떤 aggregate가 다른 aggregate의 ID 값만 가지고 있다는 것은 비즈니스 로직을 수행하기 위해 필요한 정보들을 충분히 가지고 있지 않다는 의미가 될 수 있다. 따라서, 앞서 살펴봤듯이 Vaughn Vernon과 Harry Percival 모두 application service가 aggregate의 커맨드 메서드를 실행하기 전에 미리 필요한 객체들을 repository에서 꺼내서 전달해야 한다고 언급하고 있다.
그렇지만 현실은 항상 이상적으로 흘러가지 않는다. Aggregate들을 이상적으로 잘 설계했다면, 서로를 ID 값으로 참조하는 경우가 최소화되고 자신의 비즈니스 로직 수행에 필요한 data는 값 객체 형식으로 모두 가지고 있는 형태가 될 것이다. 그런데, 실제로는 aggregate들 사이의 참조 관계가 점점 복잡해지면서, application service가 의존성을 풀어내는 과정이 매우 부담스러워지는 경우가 많다. Vaughn Vernon은 이에 대해 다음과 같이 설명하고 있다.
애플리케이션 서비스가 의존성을 풀어내게 되면, 애그리게잇은 리파지토리나 도메인 서비스에 의지할 필요가 없어진다. 하지만 매우 복잡한 도메인별 의존성을 해결하기 위해선 도메인 서비스를 애그리게잇의 커맨드 메소드로 전달하는 방법이 최선일 수 있다.
모델이 오직 ID만을 사용해 참조하도록 제한한다면 클라이언트에게 사용자 인터페이스 뷰를 조합해서 보여주기가 더욱 어려워질 수 있다. 여러분은 아마도 하나의 유스케이스에 해당하는 뷰를 만들기 위해 여러 리파지토리를 사용해야만 하는 상황에 놓일 수 있다. 쿼리의 성능에 문제가 발생한다면 세타 조인이나 CQRS의 사용도 고려해볼 만하다.
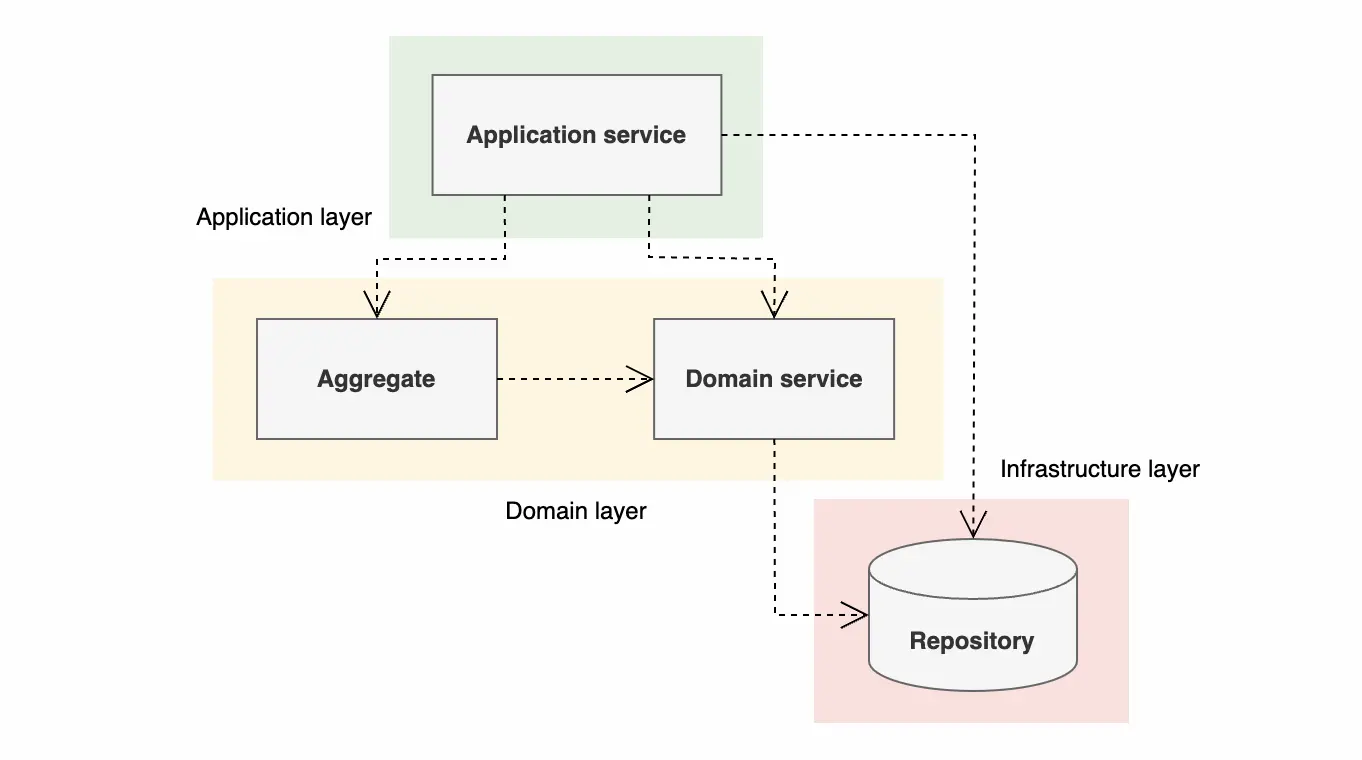
이때 domain service가 repository를 직접 사용한다면, application service의 의존성 해결 책임을 어느정도 분담할 수 있다. 그리고, application service가 aggregate에게 이러한 domain service를 전달하도록 한다면, aggregate에서는 repository를 직접 사용할 필요가 없게 된다. 즉, domain layer의 핵심인 aggregate의 관점에서만 보면, repository같은 인프라적인 요소에 직접 의존하지 않고 같은 domain layer에 위치한 domain service를 사용하는 것이기 때문에 문제가 없어보인다. 일종의 눈속임같은 것이다.
요약: domain model과 repository 의존성 설계법
일반적(이상적)인 설계 방법
- Domain model에서는 직접 repository를 사용하지 말자.
- Application service에서만 repository를 사용하자.
- Aggregate에서 다른 aggregate의 참조가 필요한 경우, application service가 필요한 객체들을 미리 repository에서 꺼내어 전달해주자.
현실의 벽에 부딪혔을 때 고려해볼 만한 설계 방법
- 의존성 해결을 위해 application service의 코드가 너무 복잡해진다면, domain service가 repository를 직접 사용해서 일부 책임을 나누는 것을 눈감아주자.
- Domain service가 의존성 해결 책임을 일부 떠맡은 경우, application service에서 aggregate에게 domain service를 인자로 전달하여 어떻게든 aggregate가 직접 repository를 사용하지 않도록 만들자.
- 의존성 주입을 통해 aggregate에 domain service를 전달하는 것은 바람직하지 않은 방법임을 기억하고, aggregate 리팩토링을 추가적으로 고려하자.

More Posts

Validation 코드는 어디에 작성해야 할까? - The 3 types of validation logics
개발자들은 다양한 validation 코드들을 작성하는데 많은 시간을 소비한다. 이곳저곳에 덕지덕지 붙어있는 validation 코드들을 바라보면, 과연 이 코드들이 여기에 있어도 되는 것인지 의문이 생긴다. 다양한 종류의 validation 코드들을 어디에 작성해야 하는지 정리해보자.

Aggregate의 문제점과 바람직한 설계 방법 - DDD aggregate diet
DDD의 aggregate는 일관성 관리를 위해 매우 중요한 개념이지만, 덩치가 커질수록 성능과 확장성 측면에서 문제가 발생하게 된다. Composition 기반 aggregate의 문제점에 대해 자세히 살펴보고, 효율적인 aggregate를 설계하기 위한 방법들을 알아보자.
Aggregate란 무엇인가 도대체! - DDD aggregate의 기초 쉽게 이해하기
DDD에서는 aggregate라는 용어가 자주 등장한다. DDD의 다양한 개념들을 이해하기 위해서는 aggregate에 대한 이해가 선행되어야 하는데, 보통 DDD 자료들에서는 aggregate에 대한 설명이 중후반부에 등장한다. DDD 초보자도 쉽게 이해할 수 있도록 aggregate를 겉핥기해보자.
Comments