객체지향 프로그래밍에서는 코드 중복 최소화 및 다형성을 위해 인터페이스나 추상 클래스를 정의하고 상속을 사용하는 경우가 많다. 그러나, 이는 도메인 주도 설계(DDD) 관점에서 항상 바람직한 것은 아니다. 영속성 domain entity를 정의할 때 상속을 사용하는 것이 적절한지, 그리고 어떤 것들을 고려해야 하는지에 대해 논의해보자.
영속성 domain entity를 정의할 때 상속을 사용해도 괜찮을까? - Repository code smell
Inheritance를 사용하고자 하는 개발자들의 욕구
"유사하지만 조금씩 차이점이 있는" 코드들을 작성하다보면, 코드 중복 최소화를 위해 상속 관계를 사용하고 싶어지는 것이 당연하다. 공통된 상태와 행동을 부모 클래스에 정의해두고, 이를 상속하는 자식 클래스들이 각자의 차이점을 구현하도록 하는 것이다.
상속 관계를 사용하는 것은 다형성 관점에서도 바람직해보인다. 클라이언트가 부모 클래스 타입의 참조를 통해 자식 클래스 인스턴스들을 상호 교체 가능하도록 만들면 다양한 사용자 시나리오를 객체지향적으로 지원할 수 있다.
그런데, DB나 파일 등에 영속적으로 저장 및 관리해야 하는 영속성 도메인 entity를 정의할 때 inheritance를 사용하면 오히려 code smell을 유발하게 된다. 따라서, DDD에서는 상속의 사용을 지양해야 한다는 목소리가 있다.
Repository에서 발생하는 code smell
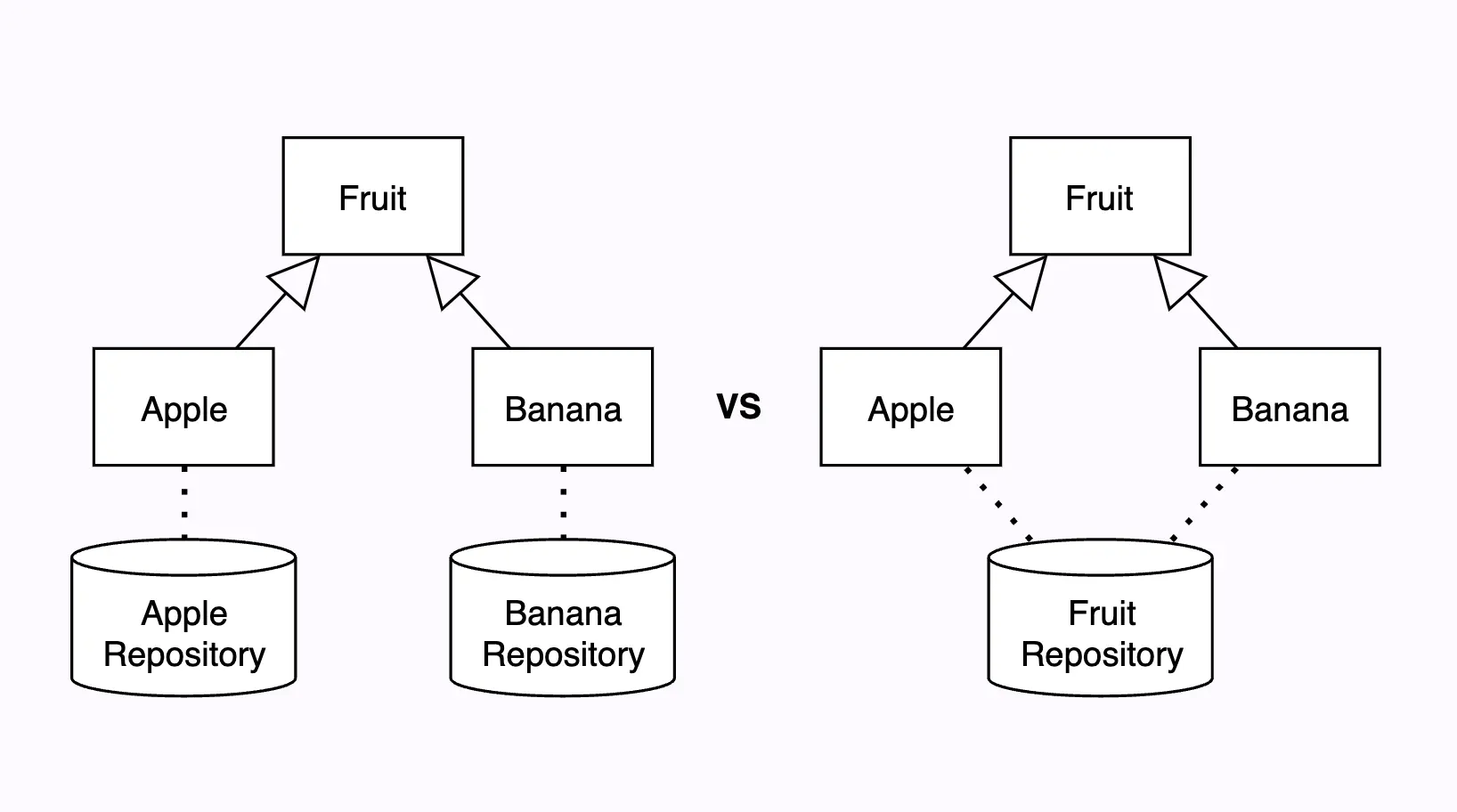
Repository 설계 방법에 초점을 맞추면, 영속성 domain entity를 정의할 때 상속을 지양해야 하는 이유를 쉽게 이해할 수 있다. Repository는 보통 주요 도메인 entity를 1:1로 전담한다. 예를 들어, Fruit라는 도메인 entity가 있다면, 이를 저장하기 위한 repository는 FruitRepository로 정의하는 식이다.
엄밀히 말하면, repository가 하나의 entity를 담당하는 것이 아니라 aggregate 하나를 담당해야 한다. Aggregate에 대한 설명은 이 글의 범위를 벗어나므로 다른 글에서 더욱 자세히 살펴보겠다. 우선 repository가 entity 하나를 1:1로 전담 마크한다고 가정하자.
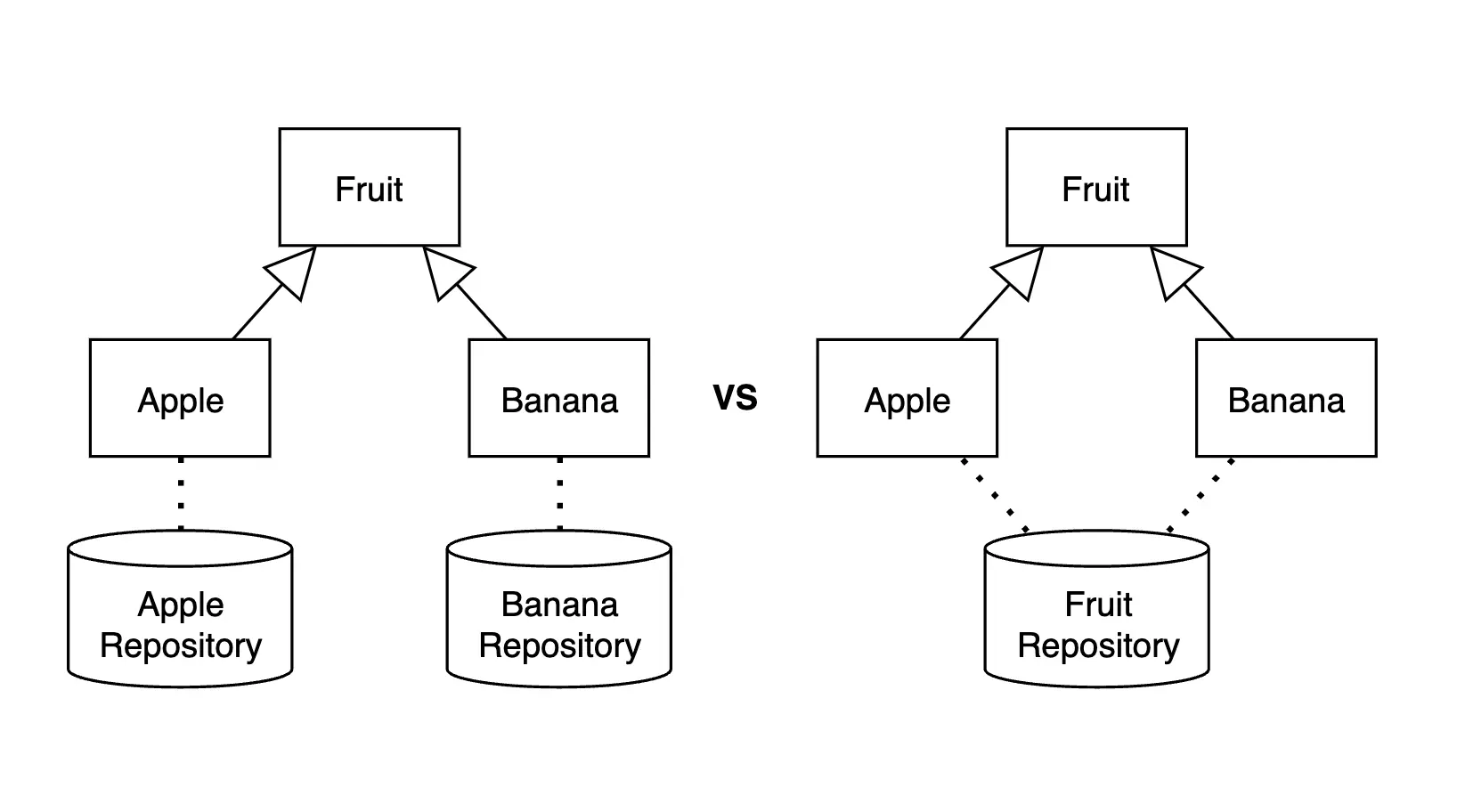
그렇다면, 공통 부모 클래스를 상속한 다양한 자식 클래스들을 관리하려면 repository는 어떻게 설계해야 할까? Repository가 담당하는 범위에 따라 크게 두 가지 방법으로 나눌 수 있다.
- 자식 클래스마다 별도의 repository 정의
- 하나의 repository에서 모든 자식 클래스들을 담당
DB 활용 관점으로 보면, 자식 클래스들을 별도의 테이블에 나누어 저장할지, 아니면 하나의 테이블에 함께 저장할지 고민하는 것이라고 이해하면 된다.
자식 클래스마다 별도의 repository를 정의한다면?
자식 클래스와 repository가 1:1 대응이 된다면, 상속을 사용하지 않았을 때의 일반적인 repository 정의와 별반 다를 것이 없다. 자식 클래스가 새로 추가될 때마다 repository의 수도 그만큼 늘어난다. 결국 repository들 사이에 코드 중복이 발생하게 된다.
하나의 repository가 모든 자식 클래스를 담당한다면?
Null로 가득하고 자주 변경되는 단일 테이블
Repository 코드를 중심으로 생각해보자. 만약 finder method가 자식 클래스 타입을 반환한다면 어떨까? 예를 들어, Fruit라는 부모 클래스를 상속하는 Apple과 Banana 클래스가 있다고 가정해보자.
class FruitRepository:
def find_apple_by_id(self, apple_id: int) -> Apple:
...
fruit = self.fruit_db.select(id=apple_id)
if fruit.type != "apple":
raise ValueError("Invalid apple.")
apple = Apple(
name=fruit.name,
size=fruit.size,
# length=fruit.length,
)
return apple
def find_banana_by_id(self, banana_id: int) -> Banana:
...
fruit = self.fruit_db.select(id=banana_id)
if fruit.type != "banana":
raise ValueError("Invalid banana.")
banana = Banana(
name=fruit.name,
# size=fruit.size,
length=fruit.length,
)
return banana
위 python 코드 예제에는 자식 클래스마다 finder method가 정의되어 있다. 이렇게 구현할 경우, 클라이언트가 메서드들을 제대로 활용하려면 지나치게 많은 정보를 알고 있어야 한다는 문제가 있다. 대표적으로 다음과 같은 책임을 떠맡게 된다.
- 각 자식 클래스마다 구분되는 식별자를 정확히 알고 있어야 한다.
find_banana_by_id메서드에apple_id를 전달한다면, 타입 캐스팅 오류같은 exception을 발생시키도록 추가적인 로직이 요구된다. - 각 자식 클래스를 인스턴스화하기 위해 필요한 attribute들을 생성자에 전달해주어야 한다.
Apple클래스에는 정의되어 있지만Banana클래스에는 없는 attribute가 존재한다면 이를 구분하여 전달할 방법이 필요하다.
이렇게 정의된 Apple과 Banana를 RDB에 저장한다고 가정해보면 얼마나 구조가 복잡해지는지 알 수 있다. 위 코드처럼 Apple에는 "size"라는 attribute가 정의되어 있고, Banana에는 "length"라는 attribute가 정의되어 있다고 생각해보자. 이 데이터를 "fruits"라는 하나의 table에 담으려면 어떻게 해야 할까? Sqlalchemy의 ORM을 기준으로 예시를 만들어보자.
from fault_manager.database import Base
from sqlalchemy.orm import declarative_base
from sqlalchemy import Column, Integer, String
Base = declarative_base()
class FruitEntity(Base):
__tablename__ = "fruits"
id = Column(Integer, primary_key=True)
type = Column(String, nullable=False)
name = Column(String, unique=True)
size = Column(Integer, nullable=True)
length = Column(Integer, nullable=True)
"size"와 "length" column이 한 테이블에 정의되어 있는 것을 확인할 수 있다. 테이블 스키마를 이렇게 정의한다면, Fruit라는 부모 클래스를 상속하는 자식 클래스가 늘어날 때마다 column이 늘어날 수 있다. 그리고, "fruits" 테이블에 수많은 null 값들이 채워지게 될 것이다.
JSON 타입 column 정의가 강제된 단일 테이블
문제를 완화하려면 각 자식 클래스들의 데이터에서 독립적으로 가지고 있는 attribute들을 저장하기 위한 JSON 타입의 column이 강제된다. "extra"같은 이름의 column으로 정의하여 임의의 데이터를 저장할 수 있도록 해주어야 한다.
from sqlalchemy import JSON
class FruitEntity(Base):
__tablename__ = "fruits"
id = Column(Integer, primary_key=True)
type = Column(String, nullable=False)
name = Column(String, unique=True)
extra = Column(JSON)
class FruitRepository:
def find_apple_by_id(self, apple_id: int) -> Apple:
...
apple = Apple(
name=fruit.name,
**fruit.extra,
)
return apple
def find_banana_by_id(self, banana_id: int) -> Banana:
...
banana = Banana(
name=fruit.name,
**fruit.extra,
)
return banana
코드를 위와 같이 작성하면 자식 클래스의 추가나 변경에 따라 테이블 스키마를 매번 변경하지 않아도 된다. 대신, 이 "extra" 컬럼에 담기는 데이터의 스키마가 row마다 달라지게 되므로 index 설정을 통해 조회를 하거나 다른 테이블과 join을 하기 위해 복잡한 코드를 작성해야 한다는 단점이 있다. 자세한 내용은 다른 글에서 다루도록 하겠다.
DB와 관련된 작업들 외에도 NoSQL적 설계를 도입하는 것과 유사하게 스키마 유효성 검증이 애플리케이션 레벨로 밀려나게 된다는 문제도 있다. 결과적으로 데이터 품질 관리나 마이그레이션 전략이 복잡해진다.
또한, 이 방식은 도메인 규칙의 명확한 표현이 아닌 구현상의 편의에 초점을 맞춘 설계로, 도메인 모델과 테이블 스키마 사이의 괴리를 키운다는 문제가 있다. ORM을 사용하는 경우 편리한 declarative 방식 대신 다소 복잡한 imperative 방식의 사용이 강제된다.
단일 finder method 정의를 통한 다형성 보완
앞서 살펴본 repository의 finder method 부분에 대해 생각하다보면 굳이 Fruit라는 부모 클래스를 상속할 필요가 없지 않냐는 의문이 든다. 다형성을 전혀 활용하지 않기 때문에 inheritance를 적용한 정당성이 약화된 것이다. 자식 클래스가 추가될 때마다 repository의 finder method를 매번 새로 작성해야 하는 것은 유지보수를 어렵게 만든다.
자식 클래스가 추가될 떄마다 사용자가 호출해야 하는 메서드가 달라진다는 점도 클라이언트에게 부담이 된다. <Implementing Domain-Driven Design>의 저자 Vaughn Vernon은 이렇게 상속에 의해 클라이언트가 많은 책임을 지게 되는 문제에 대해 다음과 같이 경고하고 있다.
클라이언트가 타입에 기반한 결정을 하지 않도록 보호하기 위해 이런 내용이 클라이언트로 누수되지 않도록 분명히 해야 한다.
다형성의 이점을 유지하기 위해서는 finder method가 추상적인 부모 클래스를 반환하도록 설계해야 한다. 하나의 finder method를 통해 다양한 자식 클래스 인스턴스를 얻을 수 있도록 만들어보자. 앞서 ORM 정의에서 "type"이라는 column을 정의해두었기 때문에 이를 활용하면 간단하게 구현할 수 있다.
class FruitRepository:
def find_fruit_by_id(self, id: int) -> Fruit:
fruit = self.fruit_db.select(id=banana_id)
if fruit.type == "apple":
return Apple(...)
elif fruit.type == "banana":
return Banana(...)
else:
...
Fruit 클래스가 Apple과 Banana가 공통으로 구현해야 하는 동작을 추상화해두었다고 가정하면 사용자가 따로 타입 체킹을 할 필요없이 find_fruit_by_id 메서드의 반환 결과를 그대로 사용할 수 있다. 조금 더 다형성을 고려한 코드라고 할 수 있다.
그런데, 이 방식은 사용자가 특정 과일 타입을 요구할 수 없다는 문제가 있다. 만약 반드시 "apple" 타입을 꺼내야 하는 사용자 시나리오가 있다면, 클라이언트 측에서 위 메서드의 반환 결과가 Apple 타입이 맞는지 검증할 책임을 가지게 된다. isinstance(result, Apple)같은 검증 코드들이 자식 클래스 수만큼 클라이언트 쪽에 작성되어야 하므로 코드 스멜이 발생한다.
식별자 클래스 정의를 통한 검증 부담 완화
보통 repository의 finder method를 구현할 때는 찾고자 하는 객체가 존재하는 경우 해당 객체를 반환하고, 존재하지 않는 경우에는 None을 반환하는 식으로 코드를 작성하는 경우가 많다. 따라서, 사용자가 일단 정체 모를 과일을 꺼낸 뒤에 Apple인지 Banana인지를 검증하기보다는, 원하는 과일 종류를 요청해보고 없을 경우 None을 응답받는 것이 자연스럽다.
Apple 또는 Banana를 선별적으로 가져올 수 있도록 하기 위해 과일의 type 정보를 포함한 FruitId라는 별도의 식별자 클래스를 정의하여 전달하면 된다. 해당 식별자에 포함된 정보를 바탕으로 특정 타입의 과일을 꺼내보고 없으면 None을 반환한다.
from typing import Optional
class FruitRepository:
def find_fruit_by_id(self, id: FruitId) -> Optional[Fruit]:
if id.get_type() == "apple":
fruit = ...
if fruit is not None:
return Apple(...)
elif id.get_type() == "banana":
fruit = ...
if fruit is not None:
return Banana(...)
else:
...
return None
이 방법을 적용하더라도 여전히 if, elif, else가 덕지덕지 붙는 code smell이 풍긴다. 자식 클래스가 추가 또는 변경될 때마다 finder method가 매번 수정되어야 한다. 그런데, 어딘가에서는 반드시 factory method의 역할을 수행해주어야 하므로 크게 신경 쓸 필요는 없다.
그래도 상속을 사용하려는 당신을 위한 지침서
영속성 domain entity에 inheritance를 적용하면 repository를 설계하기가 까다롭다는 것을 살펴보았다. 이로 인해 대부분의 경우 inheritance로 인한 이점은 매우 제한적이다. 따라서, DDD 관점에서는 영속성 domain entity에 상속을 사용하는 것을 권장하지 않는다.
만약 여러가지 문제를 내포하고 있음에도 영속성 domain entity에 상속을 사용해야 한다면, 어떻게 repository를 설계하는 것이 좋을까? Vaughn Vernon의 말을 인용하면, 다음과 같이 각자 상황에 맞는 방법을 따르면 된다.
단 두 개 정도의 구체적인 서브클래스가 필요한 경우라면 별도의 리파지토리를 생성하는 편이 최선일 것이다. 구체적 서브클래스의 수가 서넛이나 그 이상으로 늘어나고 대부분이 완전히 상호 교체 가능하도록 사용될 수 있다면, 공통의 리파지토리를 공유하는 편이 더 낫다.
정리하면, 잠재적인 자식 클래스의 종류를 고려하여 단 하나의 repository를 사용할지 다수의 repository를 사용할지 결정하면 된다. 단, 공통 repository를 사용한다면, 클라이언트의 부담을 최대한 덜어내도록 entity나 식별자 클래스 안쪽에 클래스 타입 정보를 포함하는 것이 좋다.
이렇게 복잡한 고민들을 피하고 싶다면 상속을 지양하자. 오히려 도메인 모델을 다시 설계하는 것이 더 쉬울 수도 있다. 객체지향 프로그래밍에서도 객체들 사이의 강한 의존성을 막기 위해 상속 관계보다는 포함 관계(composition)를 권장한다는 것을 명심하자.
결론: 되도록이면 영속성 domain entity에는 상속을 사용하지 말자!
- 되도록이면 영속성 domain entity에는 inheritance 사용을 지양하자.
- 자식 클래스 종류가 적다면 자식 클래스마다 개별 repository를 정의하자.
- 자식 클래스 종류가 많다면 공통 repository를 공유하도록 만들자.
- 공통 repository를 공유한다면 타입 정보를 entity나 식별자 클래스 속성에 포함시키자.
- Inheritance보다는 composition을 통해 도메인 모델을 설계하자.

More Posts
Python으로 kubernetes 노드 선택 기능을 개발하는 방법
클러스터를 구성하면 목적에 따라 노드의 역할을 구분하는 경우가 많다. 따라서, kubernetes에서 pod를 특정 노드에만 배포해야 한다는 제약사항은 당연히 나올 수 밖에 없다. Python을 통해 이를 구현하는 방법과 고려해야 할 점들에 대해 알아보자.

Python FastAPI로 파일 업로드 및 다운로드 가능한 web server 개발하기
FastAPI를 활용하면 파일을 업로드하거나 다운로드할 수 있는 web server를 매우 간단하게 구현할 수 있다. 예제 코드와 함께 최대한 간단하게 파일 업로드 및 다운로드 API를 구현하고 테스트하는 방법을 알아보자.

안전하게 무한 루프 탈출하기 - Handling SIGTERM in kubernetes with python
프로그램의 유형에 따라 명확한 종료 시점 없이 반복적인 작업을 수행해야 하는 경우가 있다. 그런데, 영원한 것은 없지 않나! 언젠가는 종료를 시켜야 한다면, 어떻게 해야 안전하게 무한 루프를 빠져나올 수 있는지 알아보자.
Comments