개발자들은 다양한 validation 코드들을 작성하는데 많은 시간을 소비한다. 이곳저곳에 덕지덕지 붙어있는 validation 코드들을 바라보면, 과연 이 코드들이 여기에 있어도 되는 것인지 의문이 생긴다. 다양한 종류의 validation 코드들을 어디에 작성해야 하는지 정리해보자.
Validation 코드는 어디에 작성해야 할까? - The 3 types of validation logics

Validation 로직에 대한 이해
Validation 로직의 종류와 위치
Validation은 검증 로직의 성격에 따라 코드의 위치가 달라진다. Validation에는 어떤 종류가 있고, 각 유형별로 어디에 코드를 작성하는 것이 좋을까? Harry Percival의 저서 <Architecture Patterns with Python>에서는 validation의 종류를 다음과 같이 세 가지로 정리하고 있다.
- 문법 검증
- 의미 검증
- 문맥 검증
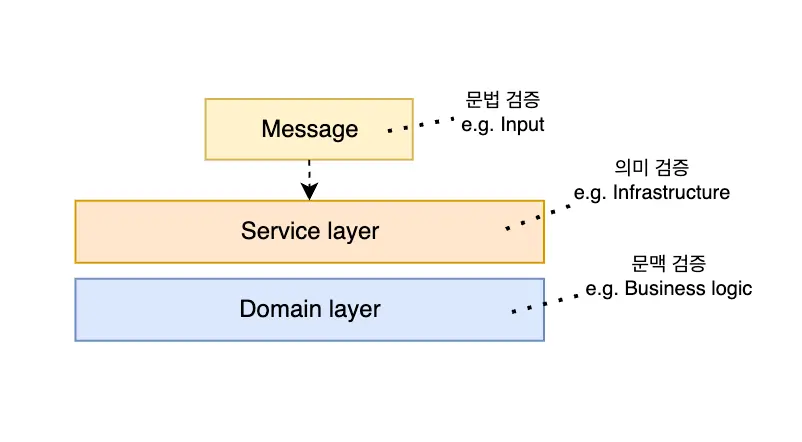
문법 검증은 최전방에서 사용자의 잘못된 입력을 검증하는 것이라고 이해하면 된다. 예를 들어, 변수에 잘못된 타입의 값이 할당되거나, 들어가서는 안되는 문자가 포함되어 있거나, 이메일이나 휴대폰 번호 등 특정 형식이 정해져 있는 문자열에 잘못된 형식의 데이터가 들어가는 경우를 검증하는 것을 생각해볼 수 있다. Harry Percival은 이러한 문법 검증이 메시지 클래스, 즉, 시스템에 흘러들어오는 데이터 객체 내부에서 수행되는 것을 추천한다.
의미 검증은 문법적으로 올바르더라도 주어진 값이 의미적으로 문제가 없는지 검증하는 단계이다. 대표적인 의미적 오류는 존재하지 않는 대상에 어떤 동작을 수행하려고 하는 경우이다. 예를 들어, "ID 값이 1인 고객에게 이메일을 보낸다"라는 말은 문법적으로 문제가 없다. 그러나, ID 값이 1인 고객이 DB에 없다면 이메일을 받을 대상이 없기 때문에 의미적으로 문제가 생긴다. 이러한 의미적 오류는 보통 DB 등 인프라와 관련된 경우가 많다. 따라서, 의미 검증은 서비스 계층에 작성하는 것이 보통이다.
문맥 검증은 문법적, 의미적으로 모두 문제가 없어보이더라도 문맥상으로 어색한 부분이 있는지 검증하는 것이다. 예를 들어, 한국어에서 "참 잘한다"라는 말은 문법적으로 올바르다. 그런데, 이 표현은 어떤 상황에서 사용되는지에 따라 적절하지 않은 표현이 될 수도 있다. 표현 자체의 의미 분석만으로는 명확한 의도를 파악하기 어렵다. 보통 이러한 문맥적인 검증은 비즈니스 로직과 관련이 있다. 다양한 도메인이 얽혀있는 복잡한 비즈니스 규칙들을 적용했을 때 문제가 없는지 확인하기 위해, 문맥 검증은 도메인 계층에 작성하는 것이 좋다.
Validation 유형의 애매모호함
사실 앞서 나눈 validation 유형은 절대적인 기준이 아니라 가이드라인에 가깝다. 실제 개발을 하다보면 특정 검증 로직이 세 가지 유형 중 어디에 속해야 하는지 정하기 애매한 경우가 많다. 따라서, 함께 개발하는 동료들과 validation 코드 작성 위치에 대한 논의와 합의 과정이 필요하다.
예를 들어, 실제 내가 참여했던 프로젝트에는 AWS나 GCP처럼 computing resource, 즉, VM 기반의 개발 환경을 사용자에게 할당해주는 기능이 있었다. 사용자가 UI를 통해 개발 환경에서 사용할 disk volume 값을 시스템에 보내게 되는데, 이때 요청하는 용량 값이 1 GiB 미만이면 오류를 발생시키는 validation이 필요했다. 이유는 특정 docker image로 개발 환경을 만들어줄 때, 기본적으로 설치되어 있는 파일들로 인해 적어도 1 GiB 정도의 disk 여유 공간이 필요할 것이라는 판단이 있었기 때문이다.
"Disk volume은 1 GiB 이상이어야 한다"는 조건은 세 가지 validation 유형 중 어디에 속한다고 볼 수 있을까? 단순히 사용자의 입력 값을 검증한다고 보면 문법 검증이 아닐까? 무언가 인프라적인 내용과 관련이 있으므로 의미 검증에 속한다고 봐야 할까? 아니면 1 GiB라는 값이 비즈니스 규칙에 해당하므로 문맥 검증이라고 봐야 할까? 내가 속한 팀에서는 다음과 같이 결정을 내렸다.
- Disk 외에 CPU, memory, GPU 등의 자원도 입력해야 한다. 각각의 자원 요청 값이 음수이면 안된다는 규칙은 문법 검증에 속한다고 판단한다.
- Disk만 예외적으로 1 GiB 이상의 값을 받아야 한다는 것은 정책적으로 기획팀과 함께 결정해야 하는 사항이 포함되므로 비즈니스적인 의도가 들어가있다고 생각한다. 따라서, 맥락 검증에 속한다고 판단한다.
결과적으로 사용자의 input을 받는 부분에 모든 자원 요청 값이 음수이면 안된다는 검증 로직이 작성되었고, 도메인 모델 쪽에 disk 값이 1 GiB 이상이어야 한다는 검증 로직이 작성되었다. Disk 요청 값에 대해 두 가지의 검증 로직이 서로 다른 곳에 작성된 것이다. 이러한 결정이 절대적인 정답이라고 생각하지는 않는다. 다만, 나름의 근거와 함께 팀원들과 합의를 통해 결정된 사항이므로 우리팀 내에서의 정답이라고 볼 수 있다.
문법 검증: pydantic validator로 코드 정리
Pydantic을 사용하자
FastAPI 등의 프레임워크를 사용하여 웹 서버 개발을 하다보면, 사용자의 입력 스키마를 pydantic으로 정의하게 된다. Pydantic의 BaseModel을 사용하면 swagger를 통해 API spec 문서를 자동으로 생성해주기도 하고, 사용자의 입력을 parsing하여 python 객체로 만들어주기 때문에 매우 편리하다.
PydanticBaseModel은 validator라는 편리한 기능을 제공해서 validation 코드들을 쉽고 깔끔하게 정리할 수 있게 도와주기도 한다. 따라서, 꼭 FastAPI를 사용하지 않더라도 메서드의 input이나 output 스키마를 정의할 때 pydantic을 사용하는 것을 추천한다. 메서드 내부에 있던 validation 코드들을 BaseModel 객체 쪽으로 분리시킬 수 있어서 가독성도 좋아지고 유지보수 측면에서도 이점이 생긴다.
Harry Percival은 문법 검증에 대해 다음과 같이 설명하고 있다. 이를 잘 숙지해두고 python의 pydantic을 활용하여 문법 검증 코드를 효율적으로 작성하는 방법에 대해 자세히 알아보겠다.
대략의 규칙은 메시지 핸들러는 항상 적격인 메시지만 받아야 하며 메시지에는 필요한 정보가 모두 있어야 한다.
Validator를 사용하지 않는다면?
만약 validator를 사용하지 않는다면 어떤 식으로 validation 코드가 작성되는지 먼저 살펴보자. Student라는 스키마에 email, name이라는 필드들을 정의해두고, 이에 대한 validation 로직을 다음과 같이 만든다고 가정해보자.
email: '@'가 포함되어 있어야 한다.age: 음수는 허용하지 않는다.
위 조건을 만족하도록 Student 클래스를 만드려면 어떻게 해야 할까? 클래스 인스턴스를 생성하는 쪽에서 validation 로직을 미리 거친 뒤 값을 넘겨줄 수도 있지만, 이는 Student 클래스를 사용하는 측에 너무 많은 책임을 전가하므로 좋지 않은 코드이다. 따라서, Student 클래스 내부에 validation 코드들을 정의해두는 편이 더욱 낫다. 대략 다음과 같이 코드를 작성할 수 있다.
from pydantic import BaseModel
class Student(BaseModel):
email: str
age: int
def __init__(self, email: str, age: int) -> None:
if '@' not in email:
raise ValueError("Email must include '@'.")
if age < 0:
raise ValueError("Age must not be a negative number.")
self.email = email
self.age = age
위 코드는 생성자에 validation 코드들을 작성한 경우이다. 이렇게 구현하면 필드 수가 증가함에 따라 생성자가 점점 거대해질 것이다. 물론 각 필드에 대한 validation 로직을 메서드로 분리하는 것도 방법이지만, 어쨌든 해당 메서드들을 호출하는 코드를 생성자에 포함시켜야 하기 때문에 여전히 불편함은 남아있게 된다. 생성자를 건드리지 않고 validation 로직을 추가하거나 수정하려면 어떻게 해야 할까?
하나의 필드 집중 검증하기
Pydantic의 field_validator를 사용하면 특정 필드에 대한 검증 로직을 깔끔하게 정리할 수 있다. 코드는 대략 다음과 같이 작성하면 된다.
from pydantic import BaseModel, field_validator
class Student(BaseModel):
email: str
age: int
@field_validator('email')
@classmethod
def validate_email(cls, value: str) -> str:
if '@' not in value:
raise ValueError("Email must include '@'.")
return value
@field_validator('age')
@classmethod
def validate_age(cls, value: int) -> int:
if value < 0:
raise ValueError('Age must not be a negative number.')
return value
@field_validator라는 decorator에 검증 대상 필드 이름을 넣어주고, 클래스 메서드로 정의하면 된다. value라는 인자에 검증 대상인 값을 받아서 검증 로직들을 수행하면 되는데, 보통 ValueError나 AssertionError를 발생시키는 식으로 작성한다. 검증 로직을 마친 뒤에는 value라는 값을 그대로 반환해주어야 한다.
>>> Student(email='user@example.com', age=-1)
...
pydantic_core._pydantic_core.ValidationError: 1 validation error for Student
age
Value error, Age must not be a negative number. [type=value_error, input_value=-1, input_type=int]
For further information visit https://errors.pydantic.dev/2.8/v/value_error
Default 값도 검증 대상에 포함시키기
field_validator 사용 시 한 가지 주의할 점은 default 값에 대해서는 기본적으로 검증하지 않는다는 것이다. 예를 들어, 다음과 같이 age의 default 값을 음수로 설정해두고 객체를 생성해보면 ValidationError가 발생하지 않는 것을 확인할 수 있다.
class Student(BaseModel):
email: str
age: int = -1
...
>>> Student(email='user@example.com')
email='user@example.com' age=-1
Default 값들도 검증 대상에 포함시키고 싶다면, pydantic의 Field에 validate_default=True를 설정하여 활용하면 된다. Student 클래스의 정의를 다음과 같이 변경하여 default 값에 대해 검증 로직이 수행되고 있음을 확인해보자.
from pydantic import field_validator, BaseModel, Field
class Student(BaseModel):
email: str
age: int = Field(default=-1, validate_default=True)
...
>>> Student(email='user@example.com')
pydantic_core._pydantic_core.ValidationError: 1 validation error for Student
age
Value error, Age must not be a negative number. [type=value_error, input_value=-1, input_type=int]
For further information visit https://errors.pydantic.dev/2.8/v/value_error
여러 필드에 공통 로직 적용하기
일부 필드들의 성격이 비슷하다면 굳이 각각 따로 검증하는 것이 아니라, 하나의 공통 validation 로직을 사용해서 코드 중복을 최소화하는 것이 좋다. 앞서 살펴본 field_validator에 여러 필드 이름을 제공하면 iteration을 돌면서 동일한 로직을 적용할 수 있게 해준다.
import pydantic import BaseModel, field_validator, ValidationInfo
from typing import Any
class Student(BaseModel)
...
@field_validator('email', 'age')
@classmethod
def validate(cls, v: Any, info: ValidationInfo) -> Any:
print(f'type={type(v)}, key={info.field_name}, value={v}')
# Write common validation code here.
return v
>>> Student(email="user@example.com", age=1)
type=<class 'str'>, key=email, value=user@example.com
type=<class 'int'>, key=age, value=1
Student(email='user@example.com', age=1)
이는 보통 비슷한 성격을 가진 같은 타입의 필드들에 대해서 사용하면 좋다. 예를 들어, first name과 last name이 둘 다 10자를 넘어야 하지 않는다는 조건을 검증하는 데 사용하면 편하다.
서로 다른 타입의 필드들에 대해 다른 로직을 적용하는 것도 가능하다. isinstance 메서드를 통해 필드의 데이터 타입마다 validation 로직을 분기시킬 수 있다.
@field_validator('email', 'age')
@classmethod
def check_alphanumeric(cls, value: str, info: ValidationInfo) -> str:
if isinstance(value, int):
print(f"Value '{value}' is int.")
elif isinstance(value, str):
print(f"Value '{value}' is str.")
else:
raise TypeError(f"Type '{type(value)}' is not supported.")
return value
>>> Student(email="user@example.com", age=1)
Value 'user@example.com' is str.
Value '1' is int.
Student(email='user@example.com', age=1)
그런데, 이 방식은 서로 다른 성격의 필드를 한 곳에서 처리하려는 시도이므로 지양하도록 하자. 이런 경우 아예 메서드를 분리하는 편이 가독성 및 유지보수 측면에서 더 낫다.
여러 필드 한꺼번에 검증하기
종종 여러 필드를 종합적으로 고려하여 validation을 수행해야 하는 경우도 존재한다. 이 경우 field_validator 대신 model_validator를 사용해야 한다. model_validator는 BaseModel를 상속받은 클래스에 정의된 모든 필드들에 접근하여 validation logic을 수행할 수 있게 해준다. 따라서, 이를 활용하면 여러 필드들을 함께 검증 로직에 포함시킬 수 있다. model_validator는 validation logic의 실행 시점에 따라 before와 after라는 두 가지 방식을 제공한다.
before 방식은 객체가 생성되기 전, 즉, 사용자가 객체 생성을 위해 생성자에 값을 전달한 시점에 validation logic을 수행하는 것을 뜻한다. 쉽게 말해서, 앞서 field_validator처럼 클래스 메서드로 정의하여 미리 사용자의 입력 값을 검증하는 "전처리" 방식이다.
after 방식은 객체가 생성되는 시점에 validation logic을 수행하는 일종의 "후처리"이다. 인스턴스 메서드로 정의하여 BaseModel 객체의 생성 과정에 담긴 필드 값들을 검증한다. 다른 필드로 인해 파생되는 필드를 검증할 때 유용하다.
from pydantic import BaseModel, model_validator
from typing_extensions import Self
from typing import Any
class Student(BaseModel):
first_name: str
last_name: str
full_name: str = ''
def __init__(self, first_name: str, last_name: str) -> None:
full_name = self._make_full_name(first_name=first_name, last_name=last_name)
super().__init__(
first_name=first_name,
last_name=last_name,
full_name=full_name,
)
def _make_full_name(self, first_name: str, last_name: str) -> str:
return first_name + ' ' + last_name
@model_validator(mode='before')
@classmethod
def check_parameters(cls, data: Any) -> Any:
if data['first_name'] == data['last_name']:
raise ValueError('First name and last name must be different.')
return data
@model_validator(mode='after')
def validate_full_name(self) -> Self:
if len(self.full_name) > 10:
raise ValueError('Full name must not exceed 10 characters.')
return self
>>> Student(first_name="hello", last_name="hello")
pydantic_core._pydantic_core.ValidationError: 1 validation error for Student
Value error, First name and last name must be different. [type=value_error, input_value={'first_name': 'hello', '...ll_name': 'hello hello'}, input_type=dict]
For further information visit https://errors.pydantic.dev/2.8/v/value_error
>>> Student(first_name="hello", last_name="world")
pydantic_core._pydantic_core.ValidationError: 1 validation error for Student
Value error, Full name must not exceed 10 characters. [type=value_error, input_value={'first_name': 'hello', '...ll_name': 'hello world'}, input_type=dict]
For further information visit https://errors.pydantic.dev/2.8/v/value_error
>>> Student(first_name="hello", last_name="test")
Student(first_name='hello', last_name='test', full_name='hello test')
before 방식의 경우 field_validator와 유사하게 클래스 메서드로 정의하며, 생성자에 전달된 parameter들을 dict 형식의 인자로 받게 된다. 해당 dict에 포함된 값들을 종합적으로 고려하여 validation logic을 작성하면 된다. Validation logic이 끝난 후에는 dict 객체를 그대로 반환해주어야 한다.
after 방식의 경우 인스턴스 메서드로 정의한다. BaseModel 객체 생성 과정에서 값을 담아둔 상태로 validation logic을 진행하는 것이므로, 객체에 포함된 값들 자체에 접근하여 validation logic을 수행할 수 있다. 따라서, 메서드에서 인자는 따로 받을 필요가 없다. Validation logic이 끝난 후에는 인스턴스 자체를 반환해주어야 한다.
참고로, after 방식의 경우 객체 생성이 모두 완료된 뒤에 수행되는 것은 아니라는 것을 주의해야 한다. BaseModel의 생성자가 호출되는 super().__init__(...) 부분 이후에 설정된 값에 대해서는 validation logic이 수행되지 않는다. 예를 들어, 위 코드에서 생성자 부분을 다음과 같이 변경해보자.
class Student(BaseModel):
first_name: str
last_name: str
full_name: str = "default"
def __init__(self, first_name: str, last_name: str) -> None:
super().__init__(
first_name=first_name,
last_name=last_name,
)
self.full_name = first_name + ' ' + last_name
@model_validator(mode='after')
def validate_full_name(self) -> Self:
print(self.full_name)
if len(self.full_name) > 10:
raise ValueError('Full name must not exceed 10 characters.')
return self
>>> Student(first_name='hello', last_name='world')
default
Student(first_name='hello', last_name='world', full_name='hello world')
super를 호출하는 부분 이후에 full_name을 변경할 경우, 변경되기 전의 값으로 validation logic을 수행하는 것을 확인할 수 있다. 따라서, 제대로 validation을 적용하려면 미리 필요한 값들을 super 호출 이전에 객체에 세팅해두어야 한다.
그런데, 제약 조건을 고려해보면 before와 after 모드 사이에 그다지 큰 차이가 없다고 생각할 수도 있다. 여러 필드 값들을 동시에 고려한다는 틀 안에서는 사용 측면에서 딱히 차이가 없는 것이 사실이다. 다만, after 모드의 경우 필드 값의 데이터 타입을 좀 더 안전하게 다룰 수 있다는 것이 장점이다. before의 경우 dict에 들어있는 값의 데이터 타입을 바로 알 수 없기 때문에 isinstance같은 메서드의 보조를 받지 않으면 실수가 나올 가능성이 상대적으로 높다.
의미 검증: 서비스 계층에 작성하기
의미 검증은 앞서 인프라적인 요소와 관련된 부분이 있기 때문에 서비스 계층에 작성하는 것이 좋다고 언급했다. 보통 서비스 계층에서는 repository에 대한 참조를 사용하기 때문에, 의미 검증 코드는 다음과 같은 형식으로 작성될 것이다.
class ApplicationService:
def __init__(self) -> None:
self.repository = Repository()
def get_info(self, id: int, session: Session) -> None:
with session() as s:
domain_entity = self.repository.read(id=id, session=s)
if domain_entity is None:
raise NotFoundError(f"Entity with ID {id} not found.")
...
"정수형의 ID를 통해 entity의 정보를 조회한다."는 문장은 문법적으로 올바르다고 볼 수 있다. 그런데, 조회 결과 해당 ID를 가진 entity가 존재하지 않는다면 정보도 없는 것에 해당하므로 의미적으로는 오류가 있다고 할 수 있다. 따라서, 이러한 의미 검증 코드는 application service 또는 handler의 메서드에 작성하면 된다. 코드 중복을 최소화하려면 이러한 검증 코드들을 별도의 메서드로 만들어두고 재활용하는 것도 좋다.
class ApplicationService
...
def _get_entity(self, id: int, session: Session) -> Entity:
with session() as s:
domain_entity = self.repository.read(id=id, session=s)
if domain_entity is None:
raise NotFoundError(f"Entity with ID {id} not found.")
return domain_entity
문맥 검증: 도메인 계층에 작성하기
문맥 검증은 앞서 비즈니스 로직과 관련된 경우가 많기 때문에 도메인 계층에 작성하는 것이 좋다고 언급했다. 따라서, domain service 또는 entity 클래스 내부에 검증 로직을 작성하면 된다.
예를 들어, "특정 ID를 가진 계좌에서 10,000원을 꺼낼 때 수수료 1,000원을 부과한다."는 규칙이 있다고 해보자. 이때, 수수료가 1,000원이라는 사실은 비즈니스 규칙에 해당한다. 보통은 "수수료율"로 관리되는 값일 것이다. 이 규칙에 의하면, 계좌에서 10,000원을 꺼내기 위해서는 11,000원이 있어야 한다는 맥락을 발견할 수 있다. 따라서, 계좌에서 돈을 꺼내기 전 11,000원이 있는지 확인하는 문맥 검증 로직은 domain model에 작성되어야 한다. Account라는 entity를 정의했다면, 코드는 다음과 같은 형식으로 작성될 것이다.
class Account:
def __init__(self, balance: int, ...) -> None:
...
self.balance = balance
self.withdrawal_fee_rate = 0.1
def withdraw(self, amount: int) -> None:
if balance < amount * (1 + self.withdrawal_fee_rate):
raise InsufficientBalanceError(f"Available balance is {balance}.")
...
Entity의 메서드 내부에 validation 코드들이 덕지덕지 붙는 것이 거슬린다면, 문맥 검증 코드들을 별도의 domain service 메서드로 만들어두거나 아예 수수료율과 관련된 규칙들을 검증해주는 전용 클래스를 만들어서 활용하는 것도 좋은 방법이다.
class WithdrawalPolicy: # Domain service
withdrawal_fee_rate = 0.1
@classmethod
def validate(cls, account: Account, amount: int) -> None:
if account.balance < amount * (1 + cls.withdrawal_fee_rate):
raise InsufficientBalanceError(f"Available balance is {account.balance}.")
...

More Posts
Python으로 kubernetes 노드 선택 기능을 개발하는 방법
클러스터를 구성하면 목적에 따라 노드의 역할을 구분하는 경우가 많다. 따라서, kubernetes에서 pod를 특정 노드에만 배포해야 한다는 제약사항은 당연히 나올 수 밖에 없다. Python을 통해 이를 구현하는 방법과 고려해야 할 점들에 대해 알아보자.

Python FastAPI로 파일 업로드 및 다운로드 가능한 web server 개발하기
FastAPI를 활용하면 파일을 업로드하거나 다운로드할 수 있는 web server를 매우 간단하게 구현할 수 있다. 예제 코드와 함께 최대한 간단하게 파일 업로드 및 다운로드 API를 구현하고 테스트하는 방법을 알아보자.

안전하게 무한 루프 탈출하기 - Handling SIGTERM in kubernetes with python
프로그램의 유형에 따라 명확한 종료 시점 없이 반복적인 작업을 수행해야 하는 경우가 있다. 그런데, 영원한 것은 없지 않나! 언젠가는 종료를 시켜야 한다면, 어떻게 해야 안전하게 무한 루프를 빠져나올 수 있는지 알아보자.
Comments