개발을 하다보면 CQRS라는 용어를 자주 만나게 된다. 특히 이벤트 기반 아키텍처나 대용량 트래픽 처리와 관련된 주제에서는 항상 빠지지 않고 등장하는 단골 메뉴다. 예제와 함께 CQRS 패턴의 정의, 장단점, 그리고 적용 방법 등을 최대한 간단하게 정리해보자.
CQRS 개념 초간단 정리 - Understanding CQRS pattern
CQRS란 무엇인가?
CQRS는 Command and Query Responsibility Segregation의 약자다. 이름 그대로 command와 query를 분리하는 패턴을 의미한다. 이때 command와 query가 무엇인지 생소한가? CQRS는 결국 "읽기"와 "쓰기"를 분리하는 것이라고 이해하면 편하다.
- Command: 데이터 저장소에 데이터 쓰기
- Query: 데이터 저장소로부터 데이터 읽기
간단한 예시를 통해 이해해보자. 블로그에 게시물(post)을 업로드해주는 web API를 개발한다고 가정한다. 각 post는 ID로 관리가 된다. 이 ID는 데이터 저장소에 post가 저장될 때 발급된다. 이때 post를 업로드하고 방금 업로드한 post 내용을 확인하는 API는 어떻게 개발해야 할까?
CQRS를 따르지 않는 방식
CQRS를 따르지 않는다면 다음과 같은 절차로 동작하는 API 하나가 탄생한다.
# POST /posts
1. Post를 DB에 업로드한다.
2. 방금 업로드한 post를 DB에서 조회한다.
3. 조회된 post 정보를 사용자에게 반환한다.
사용자가 이 "업로드" API를 호출하면 다음과 같은 값이 반환될 것이다.
# POST /posts
{
"id": 1,
"title": ...,
"content": ...,
"author": ...,
...,
}
이게 뭐 어쨌냐 싶겠지만, 생각해보면 하나의 함수에서 업로드와 데이터 조회 두 가지의 책임을 지고 있다. 단일 책임의 원칙(SRP)을 위배하고 있는 것이다. 이를 피하기 위해 읽기와 쓰기를 완전히 분리하는 CQRS 패턴을 적용해보자.
CQRS를 따르는 방식
위 예제를 CQRS를 따르는 방식으로 변경하면 어떻게 될까? 다음과 같이 서로 다른 역할을 하는 두 가지 API로 나누어서 정의하면 된다.
# POST /posts
1. Post를 DB에 업로드한다.
2. 방금 업로드한 post의 ID를 사용자에게 반환한다.
# GET /posts/{post_id}
1. "post_id"라는 ID를 가진 post를 DB에서 조회한다.
2. 조회된 post 정보를 사용자에게 반환한다.
사용자가 위 API들을 호출하면 다음과 같은 형식으로 값이 반환될 것이다.
# POST /posts
{
"id": 1
}
# GET /posts/1
{
"id": 1,
"title": ...,
"content": ...,
"author": ...,
...
}
이렇게 구현하면 SRP 원칙을 준수하는 간결한 함수들이 탄생할 것이다. 그런데, 사용자 입장에서는 이 두 가지를 별도로 조회해야 하는 것이 번거롭다고 생각할 수 있다. 애초에 post의 ID 자체는 DB랑만 밀접한 연관이 있는 것이기 때문에 사용자는 몰라도 되는 정보다.
이를 개선하기 위해 UI에서는 Post-Redirect-Get(PRG)라는 패턴을 사용한다. 백엔드에 POST 요청을 날린 뒤 응답이 오면 곧바로 GET 요청을 통해 상세 정보를 조회하는 페이지로 redirection해주는 것이다. PRG 방식은 web 개발 분야에서 권장되는 디자인 패턴이다.
사실 "CQRS를 따르지 않는 방식"에서 소개한 예시에서도 업로드 시점 이후에 언제든 post 내용을 확인하려면 GET API가 필요하긴 하다. 명확하게 읽기와 쓰기의 책임을 분리한다는 측면을 극적으로 설명하고자 조금 과장하였다.
CQRS는 도대체 왜 쓸까?
대략 CQRS가 무엇인지 감은 잡았으리라 생각한다. 그런데, 애초에 읽기와 쓰기를 분리하지 않았다면 사용자가 API 호출을 두 번해야 한다는 부담도 없고, 이를 개선하기 위해 UI에서 굳이 PRG 패턴을 적용할 필요가 없지 않았을까? 여러 사람 피곤하게 만드는데 왜 CQRS를 해야 할까?
앞선 예제처럼 겉으로 보기에는 읽기와 쓰기를 분리해야 한다는 점이 잘 와닿지 않을 것이다. 하지만, 실제 내부적으로 동작하는 과정에는 큰 차이가 있다. CQRS 패턴을 적용해야 하는 이유는 다양하겠지만 핵심만 요약하면 "성능"과 "확장성" 때문이다.
CQRS는 app의 읽기 성능을 높여준다.
CQRS를 적용한다는 것은 읽기와 쓰기를 완전히 독립적으로 구현하는 것이다. 따라서, 읽기 작업과 쓰기 작업을 각각 최적화할 수 있다. 이러한 특징에 의해 데이터 저장소에서 관리되는 객체가 복잡할수록 성능 향상 효과가 극대화된다.
많은 경우 DDD 방식으로 app을 구현한다. 꼭 DDD를 적용하지 않더라도, ORM과 RDB를 사용하지 않는 app들은 찾아보기 어렵다. 이러한 app들에서는 하나의 객체를 조립하기 위해 다양한 테이블들에 join 연산을 수행하거나 여러 번 query를 날리기 마련이다.
예를 들어, 블로그의 게시물 내용을 확인하는 페이지를 생각해보자. 게시물마다 여러 댓글을 달 수 있다면, 아마 다음과 같은 식으로 객체를 정규화할 것이다. 각 객체가 DB 테이블 하나에 매핑된다고 가정하자.
class Posts:
post_id: int
title: str
content: str
author_id: int
comment_ids: List[int]
class Users:
user_id: int
email: str
class Comments:
comment_id: int
content: str
author_id: int
이때 post 하나를 온전히 조회하기 위해서는 author_id와 comment_ids에 설정된 foreign key를 통해 DB에 join 연산을 수행하거나 여러 번 query를 날려야 한다. 이러한 객체 사이의 관계가 더욱 복잡할수록, 그리고 연결된 객체들의 수가 많을수록 DB 조회 성능이 떨어진다.
그렇다고 모든 정보를 한 곳에 모은 거대한 post 객체로 변경할 수도 없는 노릇이다. 열심히 DDD의 지침을 따르고 객체지향적 관점에서 정규화한 결과물 아니겠는가? 우선 데이터 쓰기, 즉, 객체의 상태를 변화시키는 작업에서는 위 복잡한 구조를 유지할 수 밖에 없다.
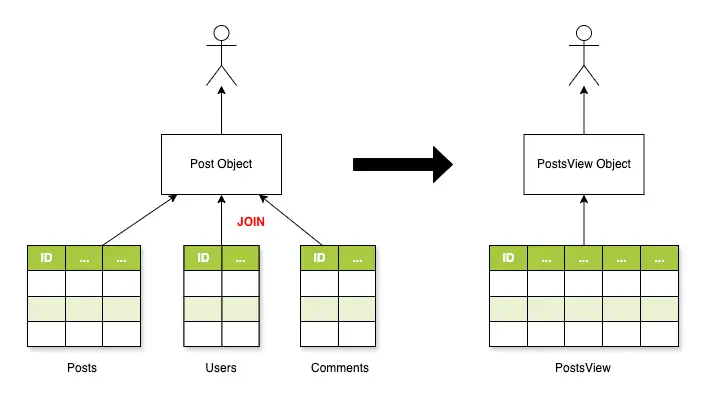
그런데, CQRS를 적용하면 읽기 작업은 따로 최적화할 수 있다. Post와 관련된 모든 정보의 복사본을 담은 별도의 view table을 만들면 된다. 왜래키를 사용하지 않고 모든 column을 flat하게 펼쳐둔 거대한 테이블을 만든다면, 간단한 쿼리로 모든 정보를 한꺼번에 조회할 수 있다.
class PostsView:
post_id: int
title: str
author_email: str
comments: List[Tuple[str, str]] # (comment_author, comment_content)
SELECT * FROM posts_view WHERE post_id = 1;
CQRS는 app의 수평확장성을 높여준다.
대부분의 app은 읽기와 쓰기의 빈도에 매우 큰 괴리가 있다. 당연히 서버에 데이터 조회를 요청하는 읽기 작업의 빈도가 압도적으로 높다. 따라서, 트래픽이 몰리는 상황에서 주로 신경써야 하는 부분은 대부분 읽기 작업의 성능이다.
CQRS는 읽기와 쓰기 작업을 독립적으로 나누는 것이기 때문에, 별도의 읽기 전용 DB나 서버를 두는 것이 가능하다. 읽기 작업은 애초에 app의 상태를 변화시키는 것이 아니다. 따라서, 여러 읽기 작업이 동시에 발생하더라도 race condition같은 복잡한 상황을 고민할 필요가 없다.
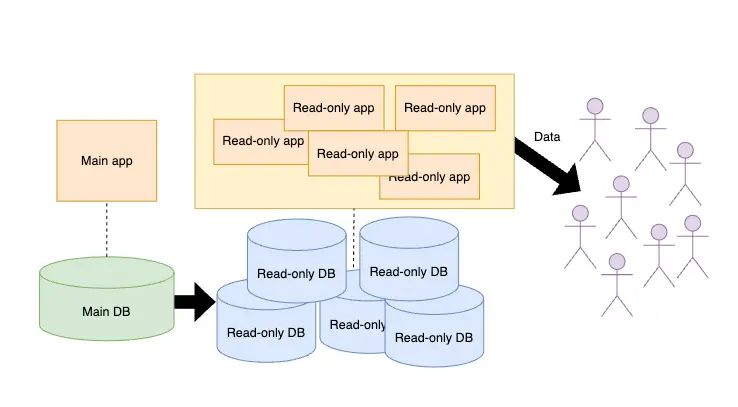
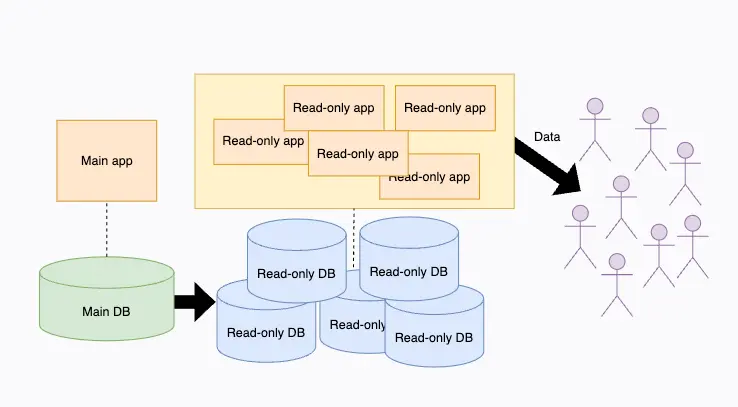
감이 오는가? 읽기 전용 DB나 서버는 트래픽 상황에 따라 큰 고민 없이 유연하게 늘리고 줄일 수 있다. Autoscaling이 가능하다! 다시 말해서, CQRS를 적용하면 읽기 작업에 대한 수평확장성이 높아지기 때문에 대규모 트래픽이 발생해도 문제없이 동작하는 app을 만들기 편해진다.
참고로 위 그림의 구조는 다소 과장된 것이다. Main app과 read-only app을 별도로 배포하면 코드 베이스를 나누어서 관리하는 불편함이 생긴다는 것에 주의하자. 보통의 경우 단일 app들을 배포한 뒤 인프라 레벨에서 로드밸런싱을 통해 트래픽을 분산하는 것으로도 충분하다.
CQRS의 문제점과 최종적 일관성
CQRS의 강력한 장점들 때문에 큰 규모의 app에서는 CQRS 패턴을 적용하는 것이 권장된다. 그런데, 안타깝게도 CQRS에 장점만 있는 것은 아니다. CQRS의 trade-off로는 흔히 "일관성 문제"가 빠지지 않고 등장한다.
앞서 읽기 성능을 향상시키기 위해 필요한 모든 정보를 담은 복사본 테이블을 만드는 방법을 살펴보았다. 이 방법을 적용하면 필연적으로 원본 테이블과 복사본 테이블의 정보가 동기화되기까지 지연이 발생한다. 읽기 전용 테이블이 항상 최신 정보를 보장해주지 않는 것이다.
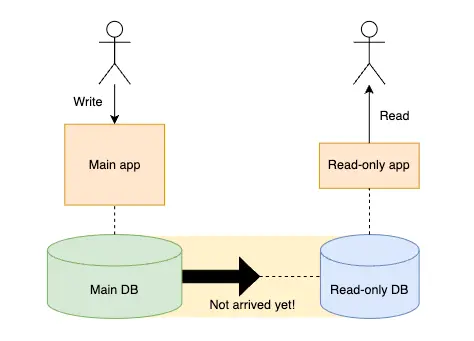
Synchronous한 방식에만 익숙한 개발자들은 이 사실을 매우 불편해할 것이다. 그런데, DDD나 EDA 등을 신봉하는 사람들은 "최종적 일관성"이라는 개념을 내세워 모두를 안심시키려고 노력한다. App을 사용하는 고객들은 대부분 인간이기 때문에, 어느 정도의 지연은 괜찮다는 주장이다.
예를 들어, SNS에 게시물 업로드 버튼을 눌렀을 때, 피드에 약 1초 뒤에 게시물이 나타난다고 생각해보자. 이 1초의 지연이 app 전체를 위험에 빠뜨리는 치명적인 문제일까? 물론 빠를수록 좋겠지만 치명적인 것은 아니다. 즉, "최종적 일관성"만 반드시 달성된다는 보장이 있다면 문제없다.
Harry Percival, Bob Gregory가 집필한 <Architecture Patterns with Python>에서는 CQRS 패턴을 적용하는 상황에서 최종적 일관성만으로도 충분하다는 메시지를 다음과 같이 전달하고 있다.
무엇을 하든, 현실은 소프트웨어 시스템과 일관성이 없다. 따라서 비즈니스 프로세스는 이런 이상한 경우를 모두 처리할 수 있어야 한다. 일관성이 없는 데이터를 근본적으로 피할 수 없으므로 읽기 측면에서 성능과 일관성을 바꿔도 좋다.
그런데, 이 주장에는 사실 숨겨진 비밀이 있다. CQRS가 적용되는 부분에 최종적 일관성이 달성되도록 신경을 써야 하며, 애초에 최종적 일관성으로도 app의 기능 동작에 문제가 없도록 app 전체를 잘 설계해야 한다는 말이 빠져있다. 이는 사실 쉬운 일이 아니다.
예를 들어, 온라인 쇼핑몰을 개발한다고 생각해보자. 고객1이 재고가 하나 남은 상품을 구매했다. 이때 재고 정보가 읽기 전용 DB에 동기화되기까지 지연이 발생한다면, 고객2가 상품 정보를 확인할 때 아무리 새로고침을 해도 재고가 남아있다고 표시될 것이다. 당연히 구매는 불가능하다.
최종적 일관성을 염두한 설계를 하는 내용은 이 글의 범위를 벗어나므로, 다른 글에서 더욱 자세히 다루도록 하겠다. 우선 최종적 일관성만 만족되어도 충분한 부분에 CQRS를 적용해야 한다는 점을 인지하고 넘어가도록 하자.
CQRS를 구현하는 방법
기존 개발되어 있던 app에 CQRS를 적용하고자 한다면, 다음 세 가지를 기억하면 된다.
- 읽기 부분에서 조회해야 하는 모든 정보를 담은 복사본 테이블을 만들어둔다.
- 기존 코드들은 그대로 두고, 읽기 부분만 별도의 함수로 떼어낸다.
- 복사본 테이블을 최신화(동기화)하는 과정을 구현한다.
읽기 전용 테이블 생성과 조회용 SQL문 작성
코드에서 활용할 객체들을 조립하기 위해 구현해두었던 코드들은 그대로 두자. 특히 ORM과 관련된 코드들을 애써 변경할 필요는 없다. 단, 정보 조회만을 목적으로 하는 use case는 별도의 함수로 구현한다. 미리 준비한 복사본 테이블에 직접 쿼리를 날리는 코드를 작성하면 된다.
def post_detail(post_id, session):
result = session.execute(
"SELECT * FROM posts_view WHERE post_id = :post_id;",
{"post_id": post_id},
)
...
ORM을 좋아하는 사람들은 이 하드코딩된 SQL문을 보고 눈살을 찌푸릴 것이다. 하지만, ORM을 사용하는 객체 구조는 읽기 연산에 최적화되어 있지 않다는 점을 인지하자. 따라서, CQRS를 사용하기로 마음을 먹었다면 SQL문을 코드에서 보더라도 "괜찮다". 관대해져야 한다.
만약 동료들이 도저히 하드코딩된 SQL문을 바라볼 수 없다며 메스꺼움을 호소한다면, ORM 문법을 사용하여 최소한의 예의를 차리도록 하자. 다음은 python에서 sqlalchemy를 사용할 때의 예시이다.
Base = declarative_base()
class PostsView(Base):
id = Column(Integer, primary_key=True)
...
def post_detail(post_id, session):
query = select(PostsView).where(PostsView.id == post_id)
result = session.scalars(query).one_or_none()
...
읽기 전용 테이블 최신화하기
읽기 전용 테이블을 최신화하는 방법은 매우 다양하다. DB 자체의 view 기능이나 trigger를 사용할 수도 있고, kafka connect를 통해 이벤트 기반으로 처리할 수도 있다. 이러한 방법들은 인프라 요소에 크게 의존하므로 자세한 내용은 다른 글에서 살펴보도록 하겠다.
인프라 요소에 기대고 싶지 않다면 모든 쓰기 작업에서 읽기 전용 테이블에도 동시에 데이터를 업데이트해주는 동기 방식을 써도 된다. 단, 이는 코드를 복잡하게 만들고 SRP를 위배하게 된다. 되도록이면 event를 활용해서 비동기적으로 최종적 일관성을 달성할 수 있는 방법을 모색하자.
요약 정리
- CQRS는 읽기와 쓰기를 분리하여 구현하는 것이다.
- CQRS를 적용하면 읽기 성능과 수평확장성이 좋아진다.
- 대용량 트래픽 처리를 위해서는 별도의 읽기 전용 DB나 서버를 두자.
- 읽기 전용 테이블의 최종적 일관성에 신경쓰자.
- 코드에서 SQL문을 보더라도 괜찮다.

More Posts

Validation 코드는 어디에 작성해야 할까? - The 3 types of validation logics
개발자들은 다양한 validation 코드들을 작성하는데 많은 시간을 소비한다. 이곳저곳에 덕지덕지 붙어있는 validation 코드들을 바라보면, 과연 이 코드들이 여기에 있어도 되는 것인지 의문이 생긴다. 다양한 종류의 validation 코드들을 어디에 작성해야 하는지 정리해보자.
Domain model에서 repository를 직접 사용해도 될까? - 도메인 모델의 영속성 무지
Repository는 인프라적인 요소에 가깝다고 할 수 있다. 그런데, 이 repository를 도메인 모델에서 직접 사용해도 괜찮을까? DDD와 관련된 여러 참고 문서들에서는 이에 대해 통일되지 않은 견해를 보이고 있다. 이 글을 통해 여러 견해들을 한꺼번에 모아서 생각해보자.

Aggregate의 문제점과 바람직한 설계 방법 - DDD aggregate diet
DDD의 aggregate는 일관성 관리를 위해 매우 중요한 개념이지만, 덩치가 커질수록 성능과 확장성 측면에서 문제가 발생하게 된다. Composition 기반 aggregate의 문제점에 대해 자세히 살펴보고, 효율적인 aggregate를 설계하기 위한 방법들을 알아보자.
Comments