Kubernetes는 클러스터에 자원이 부족한 상황에서 자원을 재분배하기도 한다. 쉽게 말해서, 어떤 앱들은 잘 동작하고 있다가도 외부의 압력으로 인해 강제로 종료될 수 있다는 의미다. 그렇다면, kubernetes는 어떤 기준으로 pod들을 종료시키는 것일까? 가장 흔히 접하게 되는 Out-Of-Memory(OOM) 현상을 위주로 살펴보자.
Kubernetes에서 memory가 부족해지면 어떻게 될까? - Kubernetes Out-Of-Memory(OOM) kill and eviction

Memory 사용을 주의하라!
CPU vs memory 뭣이 중헌디?
앞서 작성한 글에서 CPU의 request와 limit을 어떻게 설정해야 할지에 대해 살펴보았다. 실험 결과, CPU는 아무리 많이 쓰더라도 물리적인 한계, 즉, 100%를 넘게 사용할 수 없다는 것을 확인했다. CPU를 100% 사용하더라도 시스템이 강제로 종료되는 등의 치명적인 문제는 발생하지 않는다. 따라서, limit을 주지 않아도 된다는 결론을 내렸다.
그런데, memory의 경우는 어떨까? 시스템의 memory가 100% 사용되고 있다면, CPU의 경우처럼 조금 느려지는 것 외에 별다른 문제는 없는 것일까? 결론부터 말하자면, 심각한 문제가 발생한다. Memory라는 것은 프로세스가 어떤 동작을 수행하기 위해 반드시 거쳐야 하는 공간이다. 만약 pod의 memory 사용량이 설정된 limit 값에 도달하게 되면 해당 pod는 Out-Of-Memory(OOM) kill을 당한다. 쉽게 말해 pod가 죽는다는 소리다. 그렇다면 개별 pod에 memory limit을 제대로 설정하지 않아서 노드 전체 memory가 가득찬다면 어떨까? 시스템 전체가 마비될 수 있다. 따라서, CPU는 상대적으로 대충 설정하더라도, memory는 심혈을 기울여 관리해야 한다. Kubernetes 공식 문서에도 다음과 같이 memory와 disk에 대해서만 자원 재분배 동작을 수행한다고 명시되어 있다.
Evictions are supported for memory and ephemeral-storage only.
그렇다면, 자원을 효율적으로 관리해준다는 kubernetes에서는 memory 부족 현상을 어떻게 처리할까? OOM을 감지하는 방법은 무엇이며, OOM이 예상될 때 어떤 식으로 자원 재분배를 수행할까? Memory 양이 제한된 환경에서 kubernetes를 효율적으로 운영하려면 설정을 어떻게 건드려야 할까?
이 글의 목표
- Kubernetes가 OOM을 어떻게 감지하는지 이해한다.
- OOM 현상이 발생했을 때 kubernetes가 어떤 동작을 수행하는지 이해한다.
- 노드의 OOM 현상을 대비하기 위해 어떤 설정을 건드려야 하는지 파악한다.
Kubernetes가 OOM에 대처하는 방법
Kubernetes는 어떤 값을 참고할까?
Kubernetes는 클러스터의 자원 상황을 지속적으로 모니터링한다. 그리고 pod의 배포나 자원 재분배 등의 작업을 수행할 때 관측된 값들을 참고자료로 활용한다. 의사결정의 기준이 되는 값은 무엇일까?
kubectl describe node <NODE 이름> 명령어를 실행해보면, 다음과 같이 노드의 자원에 대한 capacity, allocatable, 그리고 allocated resources 값들을 확인할 수 있다.
Capacity:
cpu: 10
ephemeral-storage: 31270768Ki
hugepages-1Gi: 0
hugepages-2Mi: 0
hugepages-32Mi: 0
hugepages-64Ki: 0
memory: 24564248Ki
pods: 110
Allocatable:
cpu: 10
ephemeral-storage: 28819139742
hugepages-1Gi: 0
hugepages-2Mi: 0
hugepages-32Mi: 0
hugepages-64Ki: 0
memory: 24461848Ki
pods: 110
...
Allocated resources:
(Total limits may be over 100 percent, i.e., overcommitted.)
Resource Requests Limits
-------- -------- ------
cpu 6130m (61%) 22700m (227%)
memory 13226Mi (55%) 34074Mi (142%)
ephemeral-storage 0 (0%) 0 (0%)
hugepages-1Gi 0 (0%) 0 (0%)
hugepages-2Mi 0 (0%) 0 (0%)
hugepages-32Mi 0 (0%) 0 (0%)
hugepages-64Ki 0 (0%) 0 (0%)
가장 아래의 allocated resources 부분은 모든 pod에 설정된 request와 limit 값들의 합이라는 것을 직관적으로 알 수 있다. 그런데, 아무리 pod를 배포하고 제거해봐도 capacity와 allocatable 값들은 변하지 않는다. 이 두 값의 의미는 무엇일까?
Capacity는 node 자체의 물리적인 한계를 의미한다. 따라서, 변하지 않는 것이 당연하다. 그렇다면, allocatable은 왜 변하지 않을까? Allocated resources가 증가하면, 개념적으로는 allocatable 값들이 감소해야 하는 것 아닐까?
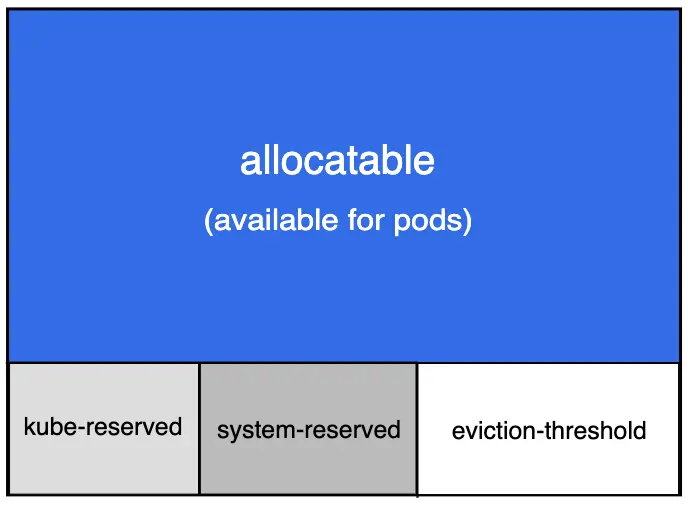
위 그림을 통해 알 수 있듯이, allocatable 값은 시스템에 의해 예약된 값들을 제외한 것을 의미한다. 그림 하단의 kube-reserved, system-reserved, 그리고 eviction-threshold 부분이 kubernetes에 의해 미리 예약된 자원을 뜻한다. 따라서, allocatable은 pod를 위해 사용할 수 있는 최대 공간을 의미하는 것이지, 아직 자원이 할당되지 않은 남은 공간을 의미하는 것은 아니다. 참고로 위 그림에서 가장 바깥 테두리는 capacity를 의미한다. Capacity에서 시스템에 의해 예약된 값을 뺀 것이 바로 allocatable 값이다.
실제로 남은 공간을 의미하는 것은 available 값이다. Kubernetes 공식 문서에 의하면, memory에 대한 available 값은 다음과 같이 구한다.
memory.available := node.status.capacity[memory] - node.stats.memory.workingSet
한 가지 주의할 점은, available 값의 의미가 "할당 후 남은 공간"이 아니라, "사용되고 있지 않은 공간"이라는 점이다. Allocation 관점이 아니라 usage 관점이다. Pod가 배포될 때 request한 양과 상관없다. Pod들의 memory 사용량 총합이 증가하면 memory.available 값은 낮아진다.
정리하자면, kubernetes가 상황별로 참고하는 값은 다음과 같다.
- Pod를 새로 배포할 때: allocated resources 부분의 requests 값 참고
- 노드 자원이 부족해서 pod를 퇴출시킬 때:
memory.available값 참고
노드의 requests 값이 100%가 되지 않도록 pod 배포를 제한하는 로직은 간단명료해서 따로 살펴볼 필요가 없다. 따라서, pod들을 퇴출시키는 방법에 초점을 맞추어 좀 더 자세히 살펴보자.
Eviction 시작 조건
Kubernetes는 자원이 부족한 상황을 감지하기 위해 다음과 같이 세 가지 요소를 고려한다.
- Eviction signals
- Eviction thresholds
- Monitoring invervals
앞서 언급했듯이, kubernetes는 memory.available 값을 통해 memory 자원의 남은 양을 판단한다. 이렇게 특정 자원의 남은 양을 모니터링하기 위한 값을 eviction signal이라고 한다. Eviction threshold라는 것은 문자 그대로 pod들을 퇴출시키는 eviction의 시작 여부를 결정할 기준 값을 의미한다. 노드의 memory.available 값이 eviction threshold 값보다 낮아지면, 해당 노드는 MemoryPressure 상태로 변경되고 eviction 과정을 통해 자원을 확보하기 시작한다. Monitoring interval은 eviction signal을 얼마나 자주 확인할지 결정해주는 값이다. 별다른 설정이 없다면 10초로 설정된다.
정리하면, kubernetes는 monitoring interval에 설정된 값(default: 10초)을 주기로 eviction signal을 확인하고, eviction signal 값이 eviction threshold에 설정된 값보다 낮아졌을 때 pod를 퇴출시키기 시작하는 것이다.
이제 앞서 살펴봤던 그림에서 우측하단의 eviction-threshold이라는 부분이 왜 별도로 allocatable 바깥에 그려져 있는지 이해할 수 있을 것이다. 노드 자원의 전체 사용량이 많아져서 자원이 eviction threshold만큼도 남지 않게 된다면 결국 eviction이 시작되어 자원을 확보하기 시작할 것이다. 다시 말해서, eviction threshold는 시스템에 의해 예약된 자원이라고 생각할 수 있는 것이다. 이 자원을 잠깐 침범하여 사용할 순 있지만, 곧 처벌(자원 회수)을 받게된다는 특징이 있다고 이해하자.
Eviction 유예 기간
Eviction이 시작되면 kubelet은 우선순위를 고려하여 선정된 pod들을 Failed 상태로 만든 뒤 종료시킨다. 어떤 pod가 우선적으로 선정되는지를 이해하려면 QoS와 PriorityClass에 대해 살펴봐야 한다. 글의 분량 조절을 위해 이 개념들은 다른 글에서 자세히 살펴보기로 하고, 우선은 eviction 발동 과정 자체에 초점을 맞춰보자.
한 가지 생각해봐야 할 것이 있다. Eviction threshold를 건드리자마자 바로 eviction이 시작되는 것이 바람직할까?
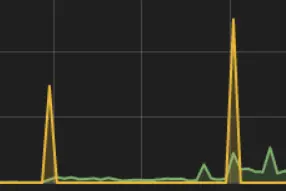
만약 위 그림처럼 memory 사용량이 일시적으로 peak를 찍고 다시 안정화되는 경우는 어떨까? 순간적인 peak 때문에, 정상적으로 동작하는 pod들을 죽이는 것은 너무 가혹하지 않을까? 이 의문에 대한 정답은 없지만, kubernetes는 클러스터 운영자에게 다음과 같이 두 가지 선택권을 준다.
- Soft eviction 방식: grace period O
- Hard eviction 방식: grace period X
Soft eviction 방식은 eviction이 발동하기 까지의 유예 기간을 주는 것이다. 반대로, hard eviction 방식은 유예 기간을 주지 않는 것이다. 유예 기간을 grace period라고 부른다. 엄밀히 따지면 grace period도 두 가지 종류가 있다.
eviction-soft-grace-period: eviction을 시작하기 까지의 grace periodeviction-max-pod-grace-period: pod가 완전히 종료될 때까지 기다려주는 grace period
첫 번째 grace period는 이미 언급했으니 넘어가겠다. 두 번째 grace period는 pod를 실제 종료시킬 때 적용되는 것이다. Pod 중에는 강제 종료되면 데이터 유실 등의 위험이 발생하는 것들이 있다. 이런 pod들은 작업하던 데이터를 DB에 저장하거나, 앱의 상태를 로그 파일에 남겨두는 등 종료 준비 작업이 필요하다. 무사히 종료 준비 작업을 마칠 수 있도록 해주어야 한다. 이를 위해 pod에 종료 신호를 보낸 뒤, 완전히 종료될 때까지 기다려주는 시간이 두 번째 grace period이다. Soft eviction 방식은 두 종류의 grace period를 둘 다 설정할 수 있다. 반대로, hard eviction 방식은 두 종류의 grace period를 아예 사용하지 않고 곧바로 pod들을 종료시켜버린다.
추가적으로 알아두어야 할 유예 기간이 하나 더 있다. eviction-pressure-transition-period이라고 부르는 녀석이다. 이는 노드의 상태를 한 번 변화시켰을 때, 다음 상태 변경까지 기다려야 하는 쿨타임같은 개념이다. Default 값은 5분이다.
Soft eviction 방식을 사용할 경우 이 쿨타임이 필요하다. 왜일까? 메모리 부족으로 eviction threshold를 만나게 되면 노드가 MemoryPressure 상태로 변경된다. 이 상태 변경은 soft eviction 방식과 무관하게 진행된다. 다시 말해서, soft eviction 방식은 eviction을 수행해야 할 시점이 오더라도 grace period 동안 기다려주는데, 그동안 노드의 상태가 계속 변할 수 있다는 뜻이다. 노드의 상태가 짧은 시간 안에 자주 변경되면 비효율적인 pod scheduling, 잘못된 eviction 등 다양한 문제를 발생시킨다. 따라서, 노드 상태 변경 주기를 늦추기 위해 eviction-pressure-transition-period가 필요하다.
어떤 설정을 건드려야 할까?
Kubelet configuration yaml
Kubelet configuration을 통해 앞서 살펴본 대부분의 값들을 변경할 수 있다. 클러스터 관리자로서 설정할 것은 eviction과 관련된 부분이다. Kubernetes 공식 문서에 자세히 나와있다. 공식 문서에서는 명령줄로 설정하는 방법을 안내하고 있지만, kubelet 설정 안내 문서에서는 다음과 같이 config 파일로 설정하라고 안내하고 있으니 주의해야 한다.
DEPRECATED: This parameter should be set via the config file specified by the kubelet's --config flag. See kubelet-config-file for more information.
Kubelet configuration yaml 파일 예시는 다음과 같다.
apiVersion: kubelet.config.k8s.io/v1beta1
kind: KubeletConfiguration
...
evictionSoft:
memory.available: "1.5Gi"
nodefs.available: "10%"
nodefs.inodesFree: "5%"
evictionSoftGracePeriod:
memory.available: "1m"
nodefs.available: "1m"
nodefs.inodesFree: "1m"
evictionPressureTransitionPeriod: "30s"
evictionMaxPodGracePeriod: 60
evictionHard:
memory.available: "1Gi"
nodefs.available: "5%"
nodefs.inodesFree: "4%"
이 글에서 다룬 내용들을 이해한 후 값을 변경해보면서 eviction이 처리되는 과정을 테스트해보자. 변경된 값을 반영하기 위해서는 config 파일 적용 및 kubelet 재시작을 잊지 말아야 한다.
개별 pod의 memory limit
노드 전체가 OOM을 최대한 겪지 않도록 하기 위해서는 개별 pod의 memory limit 설정을 잘 해줘야 한다. Limit 값을 설정하지 않으면 pod 하나가 노드 전체의 memory를 점유해버리는 극단적인 상황이 생길 수 있다. Memory limit을 설정해두면, 해당 pod만 OOM kill이 된다. 따라서, pod configuration yaml 파일의 container spec 부분에 다음과 같이 limit 설정을 해주자.
resources:
requests:
cpu: 1000m
memory: 500Mi
limits:
memory: 1Gi
그런데, 사실 모든 pod의 적절한 memory 사용량을 예측하는 것은 불가능에 가깝다. 상황에 따라 천차만별이기 때문이다. 만약 핵심적인 pod에 갑자기 사용자나 연산량이 몰려서 memory 사용량이 일시적으로 늘어난다면 어떻게 될까?
- Memory limit을 걸어둔 경우: 핵심 pod만 죽는다.
- Memory limit을 걸지 않은 경우: 전체 노드가 위험에 빠질 수 있다.
위 두 가지 경우만 보더라도, 핵심 pod에도 limit을 무조건 설정하는 것이 바람직해보인다. 그런데, 핵심 pod가 죽으면 어짜피 다른 모든 pod들의 동작이 의미가 없어지는 경우라면 어떨까? 예를 들어, 웹 서비스에서 backend 서버나 database 등이 아예 죽어버린다면 거의 모든 동작의 정상 수행이 불가능하지 않겠는가?
정확한 자원 사용량 예측이 불가능하다는 특징 때문에 보통의 경우에는 핵심 pod들의 memory limit을 크게 설정하게 된다. 그 결과로, pod들의 memory limit 값 합산이 노드의 capacity를 넘어서게 된다. 이는 결국 노드 전체가 OOM의 위험에 노출된다는 뜻이다.
따라서, 최종적으로 고려해야 할 것은 "죽는 순서"라고 할 수 있다. 다시 말해서, eviction 과정을 통해 pod를 퇴출시킬 때 어떤 순서로 퇴출시킬 것인지가 중요하다는 뜻이다. 핵심 pod들은 최대한 늦게 퇴출시키고, 일시적으로 중단되더라도 서비스 운영에 문제가 없는 pod들부터 퇴출시켜야 한다.
Pod의 퇴출 우선순위에 대해 이해하기 위해서는 앞서 잠깐 언급했던 QoS와 PriorityClass라는 개념을 살펴봐야 한다. 분량 조절을 위해 이 두 가지 개념에 대해서는 다른 글에서 다루도록 하겠다. 살짝 스포를 하자면, memory request와 limit 값을 어떻게 설정하느냐에 따라 pod 퇴출 우선순위가 달라진다는 내용, 그리고 직접 퇴출 우선순위를 지정할 수도 있다는 등의 내용이다.

More Posts
Telepresence로 kubernetes 도메인 localhost에서 훔쳐쓰기
Kubernetes에 배포된 pod들끼리 통신을 할 때는 클러스터 도메인 주소를 사용한다. Web app 개발 시 로컬에서는 localhost 주소를 주로 사용하기 때문에 다른 pod들과의 통합 테스트를 하기가 어렵다. Telepresence로 로컬에서 kubernetes의 traffic을 훔치는 방법을 알아보자.

Cache invalidation 전략
Cache는 일종의 임시 data이다. DB의 내용이 변경된다면 cache도 따라서 최신화되어야 한다. Cache에 오래된 data가 남아있으면 사용자에게 잘못된 정보를 제공할 수도 있다. 따라서, 유효하지 않은 cache data를 무효화하는 것이 중요하다. 다양한 캐시 무효화 전략을 살펴보자.

Next.js 정적 사이트 효율적으로 배포하기 - Deploying Next.js static exports with bash
콘텐츠가 많다면 정적 사이트를 웹 서버에 배포할 때 지나치게 오랜 시간이 걸릴 수도 있다. 배포 과정이 길어지면 여러가지 문제가 발생할 수 있다. 제한된 환경에서 추가적인 도구없이 딱 필요한 파일들만 파악하여 웹 서버에 전송해주는 bash script를 작성해보자.
Comments